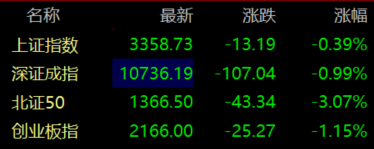
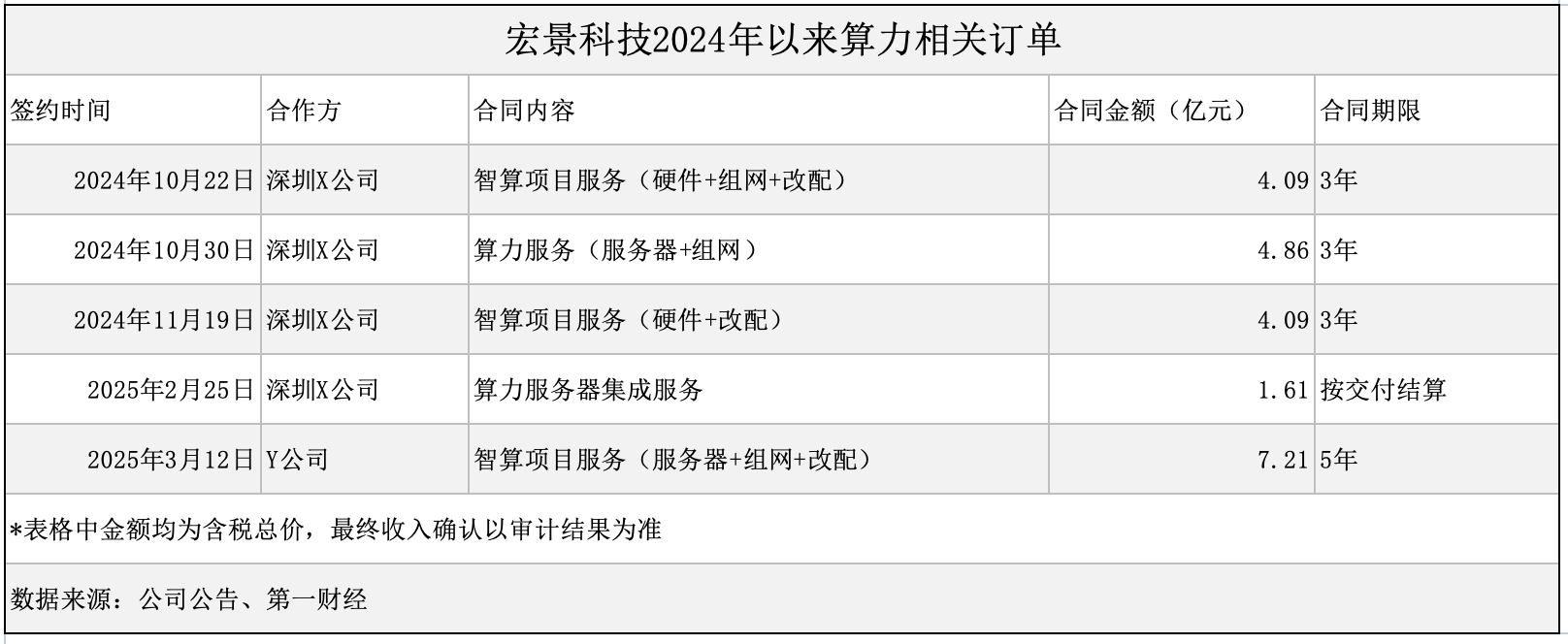
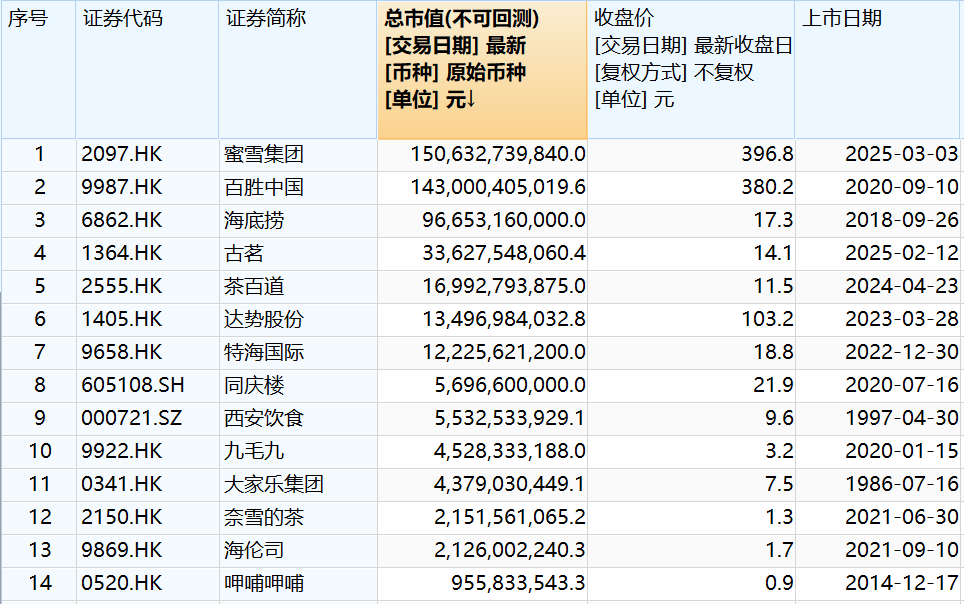
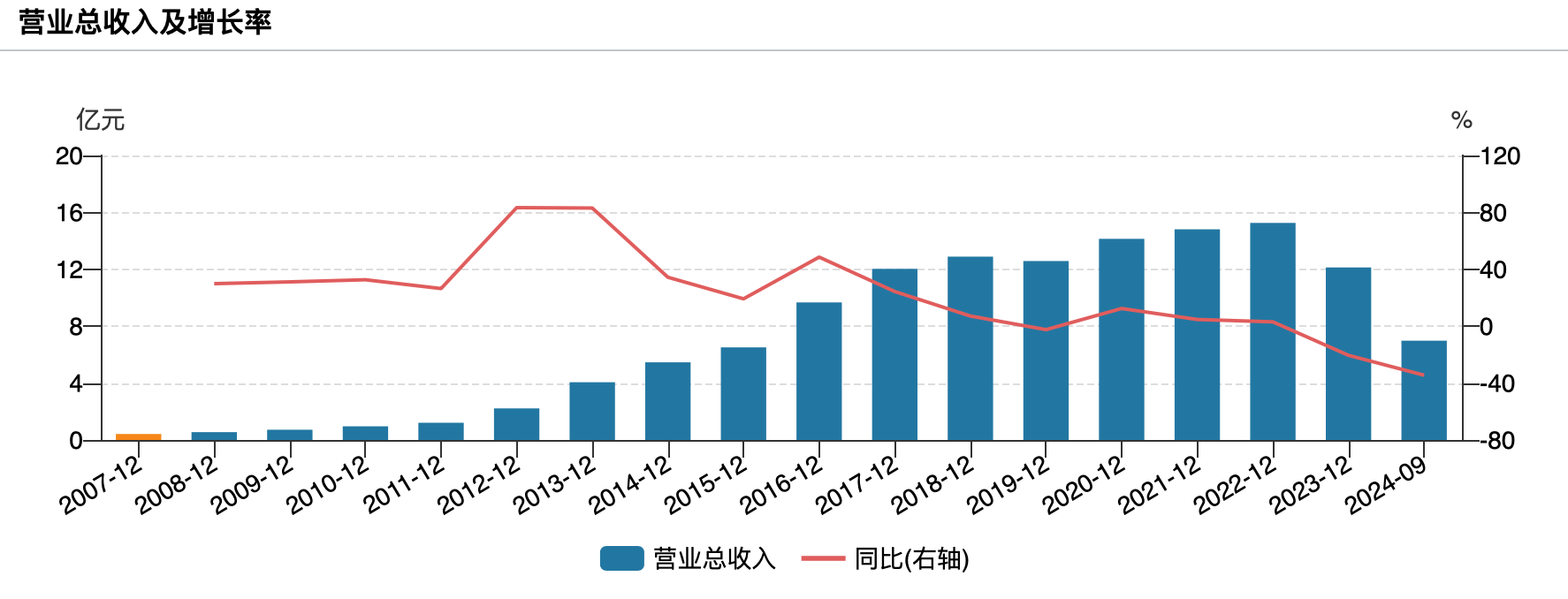
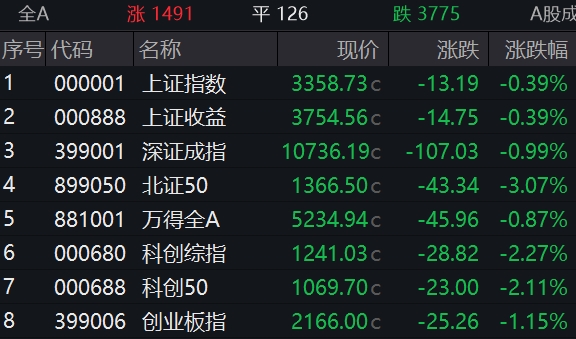
国内大模型与GPT-4较高下:语言知识能力接近,复杂推理仍是短板
1月30日,上海人工智能实验室发布了大模型开源开放评测体系司南(OpenCompass2.0),同时在对部分主流大模型评测诊断的基础上,揭晓了年度大模型评测榜单,提到了国内大模型的优势与短板。
根据评测,复杂推理相关能力是大模型普遍面临的难题,国内大模型相比于GPT-4还存在差距,这是大模型在金融、工业等要求可靠的场景落地需要的关键能力。不过,在中文场景下国内最新的大模型已展现出独特优势,尤其在语言、知识维度上接近GPT-4 Turbo的水平。
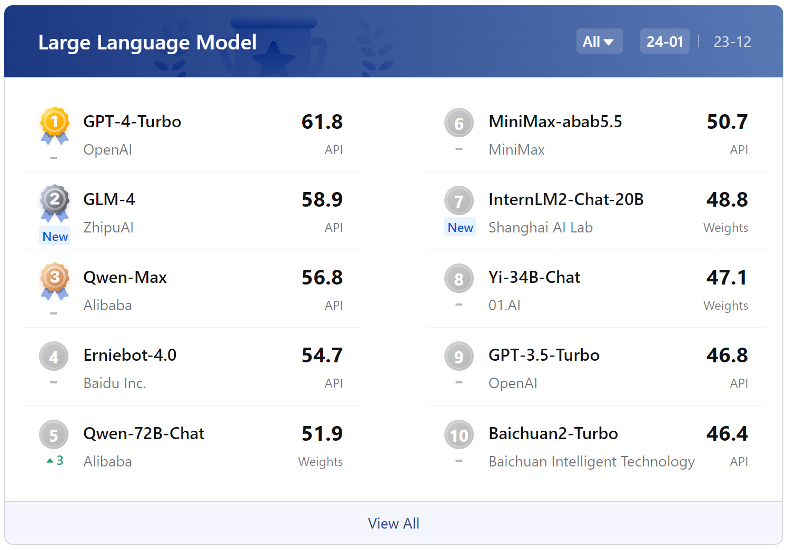
在客观评测能力排行上,整体来看大语言模型整体能力仍有较大提升空间。在百分制的客观评测基准中,GPT-4 Turbo(升级版GPT-4)在各项评测中均获最佳表现,也仅达到61.8分的及格水平。
OpenCompass2.0的分析结果显示,不少国内厂商近期新发布的模型在多个能力维度上正在快速缩小与GPT-4 Turbo的差距,包括智谱清言GLM-4、阿里巴巴Qwen-Max、百度文心一言4.0的排名较为靠前,反映了这些新模型具有较为均衡和全面的性能。
值得一提的是,此次大模型排行并未纳入所有大模型企业,各家迭代版本时间不尽相同。上海人工智能实验室方面表示,更多企业在陆续发布新的大模型,一些企业近期也有发布新版本的计划,所有这些新的大模型会进入下一期榜单上。
根据客观评测结果,部分大模型分数与GPT-4 Turbo已接近,但这并不意味着国内大模型与GPT-4 Turbo差距很小。上海人工智能实验室青年科学家陈恺对第一财经解释,分数是由不同的维度组合而来,国内的大模型和GPT-4 Turbo在不同的维度上表现并不一样,有些维度如知识、语言上可能打得有来有回,有些维度如推理上还存在着一定的差距,评测本身也会有局限性。
“出什么样的题目去考察知识边界会有区别,如果都出竞赛题,可能一个0分一个100分,出高考题那可能就是一个80分,一个90分。”陈恺表示,评测是一个整体普适性的比较,作为一个综合评测在难度上会相对平衡,虽然国内大模型与GPT-4的差距在缩小,但也不能忽视我们在复杂推理场景有大的进步空间。
从具体指标来看各个大模型的能力或许更为全面。OpenCompass2.0有客观评测和主观评测,大致类似考试中的客观题与主观题,总体上从语言、知识、创作、推理、数学、代码、智能体等方面对大模型的能力进行评测,在图中能力项颜色条越长代表能力越高。
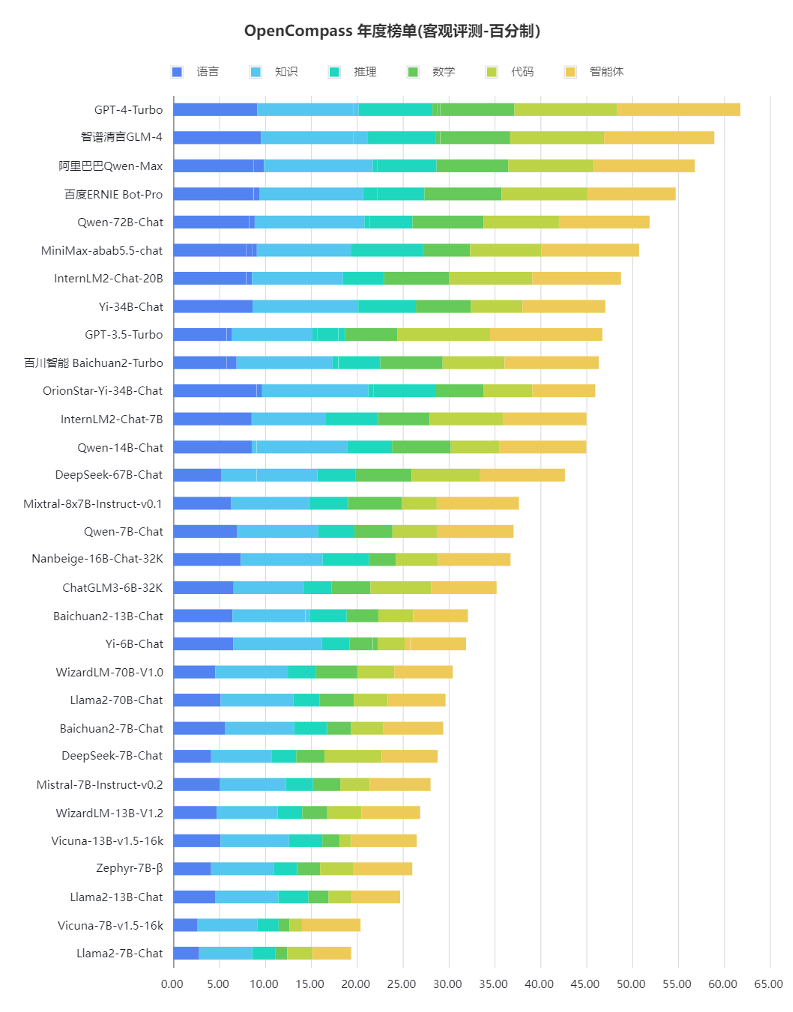
评测显示,推理、数学、代码、智能体是国内大模型的短板。GPT-4 Turbo在涉及复杂推理的场景虽然亦有提升空间,但已明显领先于国内的商业模型和开源模型。国内大模型要整体赶超GPT-4 Turbo等国际顶尖的大模型,在复杂推理、可靠地解决复杂问题等方面,仍需下大功夫。
复杂推理会如何影响大模型的能力?上海人工智能实验室领军科学家林达华对第一财经介绍,这关系到落地应用时大模型的可靠性,例如在金融这样的场景下不能在数字上有差错,会对数学上的可靠性有较高的要求。另外随着大模型进入商用,若要分析一家公司的财报,甚至是工业领域要去分析一些技术文档,这时数学方面的计算能力就会成为一个壁垒。
“现在很多大模型的应用场景是客服、聊天等等,在聊天场景一本正经胡说八道影响不太大,但它很难在非常严肃的商业场合去落地。”林达华表示。
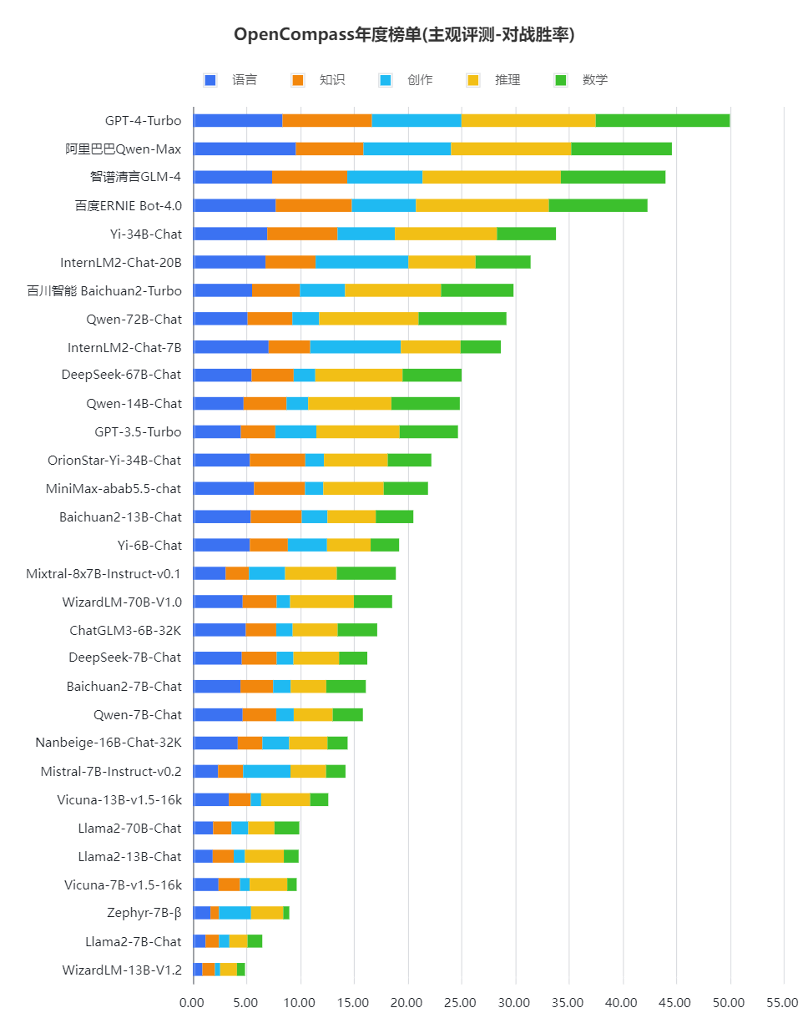
在与GPT-4 Turbo的比较中,国内大模型也有一些优势,如在主观评测中,国内模型在中文场景下相比海外模型具有性能优势,在中文语言理解、中文知识和中文创作上,国内商业模型相比GPT-4 Turbo具有极强的竞争力,甚至部分模型实现了部分维度上对GPT-4 Turbo的超越。
作为大模型的评测体系,OpenCompass于2023年7月推出,是Meta官方推荐的四个能力评测工具之一,且是其中唯一由中国机构开发的评测工具。林达华介绍,评测体系借鉴的是高考的经验,评测时这些模型题目并未公开,会避免一些模型对着题目“刷题”从而存在作弊现象,最后高考成绩某种意义上是相对较公允的评价。到榜单发布时,会将这一期榜单的题目公开,这样相关各方可以验证评测的分数。
林达华认为,关于评测,排名可能并不是最需要关注的,在榜单上一时的排名高或低并不能真正反映大模型的能力,评测的真正价值是帮助机构和企业发现自家大模型进一步需要努力的方向。
如何推动公立医院改革与高质量发展?国家卫健委解答
从国家层面我们联合有关部门印发了在医疗服务价格改革、医保支付改革、薪酬制度改革等方面的政策文件,同时实施推进了一系列的高质量发展行动。10月19日,国家卫生健康委就公立医院改革与高质量发展举行发布会。0000聚焦新能源汽车,上海召开“专精特新”产业协同发展与创新大会
上海加码助力“专精特新”企业融入新能源汽车产业生态圈。聚焦新能源汽车产业,由上海市中小企业发展服务中心、上海汽车集团股份有限公司共同组织的2023上海“专精特新”企业产业协同发展与创新大会于12月21日召开。0000欧盟将发布2040气候目标,关键原材料来源或成掣肘
欧洲政策研究中心研究员莱赫提认为,这些目标“不可行”。根据欧盟委员会日程表,欧盟将于2月6日发布2040年气候目标,以推动可再生能源进一步增长、能源节约和绿色技术的加速使用。欧委会在其影响评估中提出,为了加速清洁技术的应用,欧盟需要大量增加关键原材料的供应。例如,欧盟电动汽车电池和固定电池每年将需要8万吨锂和6万吨钴,2022年全球锂需求量为13万吨,钴需求量约为20万吨。锤子财富2024-01-25 18:57:440000双11的“别样生意”,揭秘最硬核国货购物车由来
电商平台加大国重器的组合让许多人意想不到,但这一次“混搭”并非心血来潮。赶在双11之前,淘宝上新了一批看得到、买不起、一般人还都说好的“硬核国货”,一口价999999元。这是淘宝店铺“国资小新”的第三年上新,页面展示的商品包括全球最大直径竖井掘进机、全球最大吨位桥面吊机等商品。“国资小新”由国务院国有资产监督管理委员会(下称“国资委”)下属机构负责运营。锤子财富2023-11-01 14:00:450000民营经济促进法立法进程加速,法律保障民企平等待遇“落下来”
全国人大财经委称,民营经济发展促进法等30件议案涉及的22个立法项目确有立法必要,建议有关部门加强调研论证,条件成熟时,争取列入全国人大常委会今后立法规划或年度立法工作计划。民营经济立法的呼声在今年初获得了立法机关和政府部门的明确回应,民营经济促进法的立法进程有望加速。0000