“我的画被偷了?” AI生成图片著作权侵权第一案判决书出炉
近日,北京互联网法院针对人工智能生成图片(AI绘画图片)著作权侵权纠纷作出一审判决。截至目前,该案为AI生成图片相关领域著作权第一案。
北京互联网法院民事判决书显示,原告在诉讼请求中表示被告未获得原告许可,截去了原告在小红书平台的署名水印,使得相关用户误认为被告为该作品作者,严重侵犯了原告享有的署名权及信息网络传播权。
被告辩称:不确定原告是否享有涉案图片的权利,被告所发布主要内容为原创诗文,而非涉案图片,且没有商业用途,不具有侵权故意。
最终法院评判:《中华人民共和国著作权法》(以下简称著作权法)第三条规定:“本法所称的作品,是指文学、艺术和科学领域内具有独创性并能以一定形式表现的智力成果。”根据上述规定,审查原告主张著作权的客体是否构成作品,需要考虑如下要件:是否属于文学、艺术和科学领域内;是否具有独创性;是否具有一定的表现形式;是否属于智力成果。本案中,从涉案图片的外观上来看,其与通常人们见到的照片、绘画无异,显然属于艺术领域,且具有一定的表现形式,具备了要件1和要件3。
关于“智力成果”要件,“智力成果”是指智力活动的成果。因此,作品应当体现自然人的智力投入。本案中,原告发布涉案图片时已经标注为“AI插画”,且原告可以利用Stable Diffusion模型根据自己设定的提示词和参数还原该图片的生成过程,在无相反证据的情况下,可以认定涉案“春风送来了温柔”图片系原告利用生成式人工智能技术生成的。根据公开资料和相关调研显示,Stable Diffusion 模型是由互联网上大量图片和其对应文字描述训练而来,该模型可以根据文本指令,利用文本中包含的语义信息与图片中包含的像素之间的对应关系,生成与文本信息匹配的图片。
本案中,原告希望画出一幅在黄昏的光线条件下具有摄影风格的美女特写,其随即在Stable Diffusion模型中输入了提示词,提示词中艺术类型为“超逼真照片”“彩色照片”,主体为“日本偶像”并详细描绘了人物细节如皮肤状态、眼睛和辫子的颜色等,环境为“外景”“黄金时间”“动态灯光”,人物呈现方式为“酷姿势”“看着镜头”,风格为“胶片纹理”“胶片仿真”等,同时设置了相关参数,根据初步生成的图片,又增加了提示词、调整了参数,最终选择了一幅自己满意的图片。
从原告构思涉案图片起,到最终选定涉案图片止,整个过程来看,原告进行了一定的智力投入,比如设计人物的呈现方式、选择提示词、安排提示词的顺序、设置相关的参数、选定哪个图片符合预期等等。涉案图片体现了原告的智力投入,故涉案图片具备了“智力成果”要件。
对于涉及人工智能等前沿技术所引发的著作权问题,法院认为,如今智能手机的照相功能越来越强大,使用越来越简单,但是只要运用智能手机拍摄的照片体现出了摄影师的独创性智力投入就仍然构成摄影作品,受到著作权法保护。技术越发展,工具越智能,人的投入就越少,但是这并不影响我们继续适用著作权制度来鼓励作品的创作。在上述人工智能模型出现以前,人们需要花费时间精力去学习一定的绘画技能,或者需要委托他人,才能获得一幅绘画作品。
在委托他人绘画的场景下,委托人会提出一定的需求,受托人根据委托人的需求动笔去画出线条、填充色彩进而完成一幅美术作品。在委托人与受托人之间,一般来讲,动笔去画画的受托人被认为是创作者。这种情形与人利用人工智能模型生成图片的情形类似,但是两者有一个重大的区别,即受托人有自己的意志,其在完成委托人委托的绘画工作时,会在绘画中融入自己的取舍和判断。
而现阶段,法院认为,生成式人工智能模型不具备自由意志,不是法律上的主体。因此,人们利用人工智能模型生成图片时,不存在两个主体之间确定谁为创作者的问题,本质上,仍然是人利用工具进行创作,即整个创作过程中进行智力投入的是人而非人工智能模型。鼓励创作,被公认为著作权制度的核心目的。只有正确地适用著作权制度,以适当的法律手段,鼓励更多的人用最新的工具去创作,才能更有利于作品的创作和人工智能技术的发展。在这种背景和技术现实下,人工智能生成图片,只要能体现出人的独创性智力投入,就应当被认定为作品,受到著作权法保护。
而涉案人工智能模型设计者既没有创作涉案图片的意愿,也没有预先设定后续生成内容,其并未参与到涉案图片的生成过程中,于本案而言,其仅是创作工具的生产者。其通过设计算法和模型,并使用大量数据“训练”人工智能,使人工智能模型具备面对不同需求能自主生成内容的功能,在这个过程中必然是进行了智力投入,但是设计者的智力投入体现在人工智能模型的设计上,即体现在“创作工具”的生产上,而不是涉案图片上。
故法院裁定:涉案人工智能模型设计者亦不是涉案图片的作者。
此外,本案中,从相关主体的约定来看,根据在案证据,涉案人工智能模型的设计者,在其提供的许可证中表示,“不主张对输出内容的权利”,可以认定设计者亦对输出内容不主张相关权利。
如前所述,原告是直接根据需要对涉案人工智能模型进行相关设置,并最终选定涉案图片的人,涉案图片是基于原告的智力投入直接产生,且体现出了原告的个性化表达,故原告是涉案图片的作者,享有涉案图片的著作权。
同时法院强调称,虽然本案认定原告作为作者享有著作权,但根据诚实信用原则与保护公众知情权的需要,原告应该显著标注其使用的人工智能技术或模型。
目前国内多款大模型产品已上线文生图功能,包括腾讯、百度、阿里等平台。此前腾讯混元大模型披露文生图功能,关于AI文生图可能引发的版权与著作权问题,腾讯混元大模型文生图技术负责人芦清林对记者表示,一方面是训练数据需要把控好,包括公开数据集与采买数据集,腾讯花费了一定成本来确保版权问题,同时对敏感数据进行规避。
上海理振律师事务所律师李振武在微博评论该案件称:法官已经很小心地在进行论证了,花费很多篇幅解释生成过程中原告的参与度,为了说明原告的文字描述和指示具有独创性,体现了原告的审美选择。但如果不同的人按照这一套同样的文字描述和指示能得出同一张照片的话,独创性的体现就是“原告独立想出来这些描述和指示”,因为如果不是原告这样描述,就得不出这张照片,这里面AI只是工具。
李振武认为本案作为个案,不具有认定趋势的意义,本案与直接生成AI作品的案例不同,法官也在判决书中用了大量篇幅论证原告的参与度。
盘前必读丨十四届全国人大二次会议在京闭幕;美股收盘涨跌互现
机构表示,预计金价中长期稳步上行。财经日历:15:00德国2月CPI年率终值(%)15:00英国1月失业率-按ILO标准(%)20:30美国2月CPI年率未季调(%)20:30美国2月核心CPI年率未季调(%)20:30美国2月能源CPI年率-未季调(%)周一(3月11日),美国三大股指收盘涨跌不一,道指涨0.12%,标普500指数跌0.11%,纳指跌0.41%。锤子财富2024-03-12 08:04:560000沪指失守2800点 两市超4900只个股下跌 机构解读后市
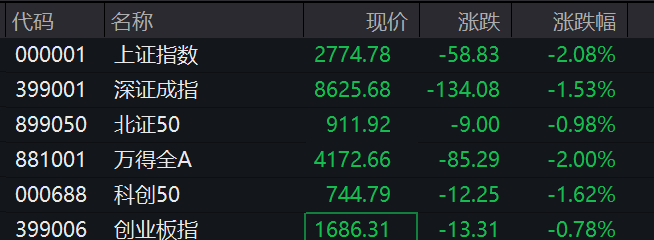
沪指盘中跌破2800点,创2020年4月以来新低,截至发稿,沪指跌超2%,深成指跌1.53%,创业板指跌0.78%。1月18日,A股再次跌上热搜。沪指盘中跌破2800点,创2020年4月以来新低,截至发稿,沪指跌超2%,深成指跌1.53%,创业板指跌0.78%,超4900只个股下跌。板块方面,酒店及餐饮、旅游、零售、煤炭板块跌幅居前,BC电池板块逆市飘红。后市怎么走?锤子财富2024-01-18 11:34:000000共创可持续未来!南方基金发布《2023年资产所有者ESG调查报告》
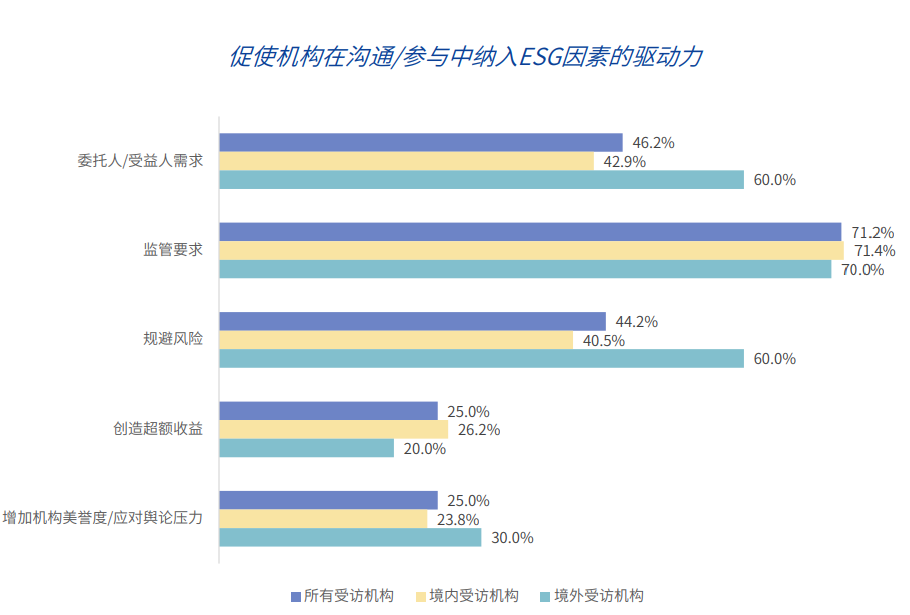
10月16-20日,联合国第八届世界投资论坛在阿拉伯联合酋长国首都阿布扎比举行。本次论坛以“投资于可持续发展”为主题,旨在为应对全球投资和发展挑战制定战略与解决方案。锤子财富2023-10-26 10:56:310003超五成A股房企上半年预亏,总亏损额超120亿元
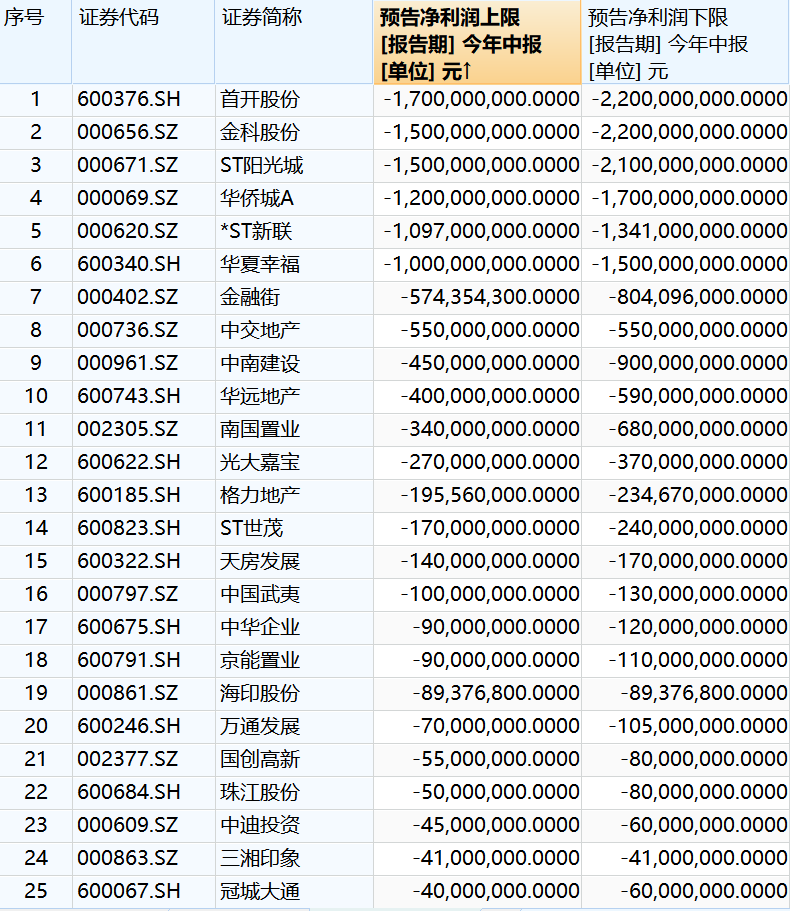
已有38家A股房企发布了预亏损公告。在房地产行业回暖不明显的上半年,A股预计亏损的房地产企业已超过一半。截至8月4日,wind行业分类的116家A股房地产企业中,已经有68家披露了上半年业绩预告,其中,有38家房企均预计亏损,也就是说,已披露业绩预告的房企中,超过半数房企预计亏损。另外,据第一财经统计,上述亏损的38家房企亏损的总额范围为120亿元~170亿元。锤子财富2023-08-04 21:32:000000