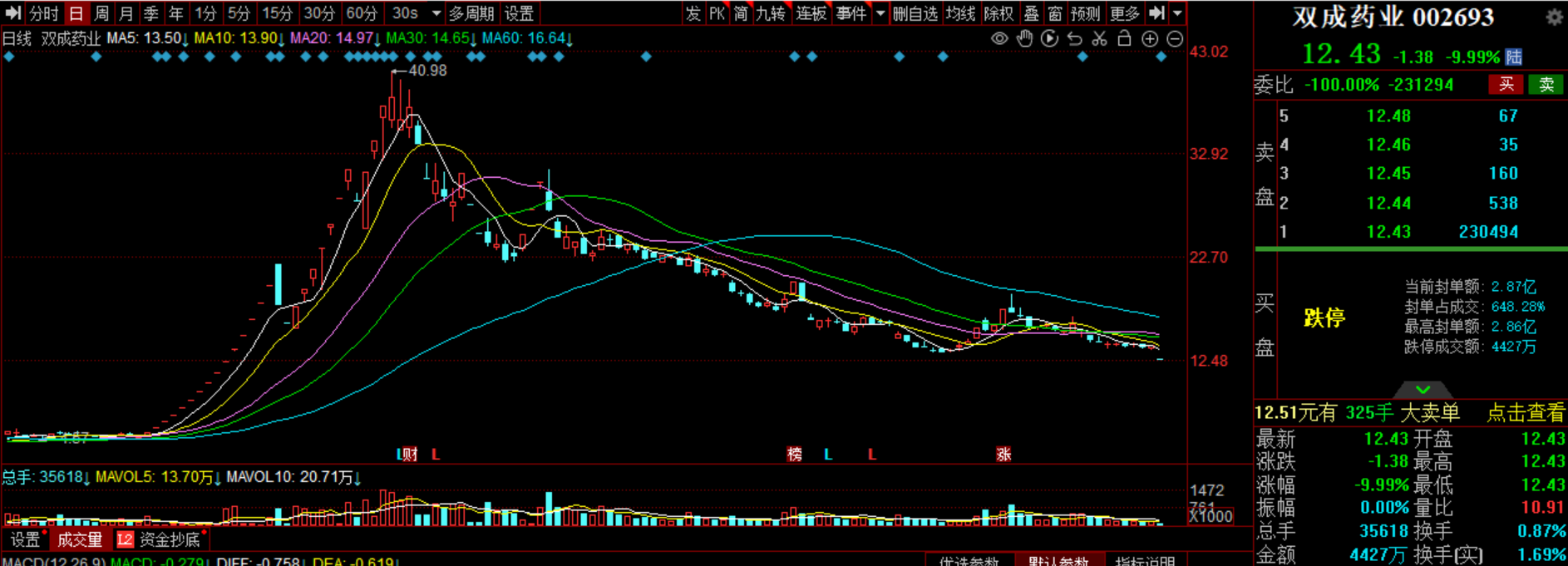
Scaling Law、多模态、价格战,智源大会成AI春晚
6月14日至15日,“2024北京智源大会”在京举行。现场,OpenAI Sora负责人Aditya Ramesh(阿迪提亚·拉梅什)进行技术分享,零一万物CEO、创新工场董事长李开复与中国工程院院士张亚勤炉边对话,国内大模型创业公司“四小龙”罕见同台。
智源研究院是在国家科学技术部和北京市委市政府的指导下,由北京市科委和海淀区政府于2018年11月成立的新型研发机构。2023年,原院长黄铁军从张宏江理事长手上接过理事长的“接力棒”,新任院长由王仲远出任,后者曾是快手技术副总裁。一年一度的智源大会被行业称为“AI春晚”。
现场,科技部战略规划司副司长康相武表示,当前,人工智能正处在群体性技术变革的起点,正迈向多智能融合的新阶段,将成为第四次工业革命的标配,引发社会发展深远变革。人工智能的大规模跨界应用也将带来多重安全风险挑战。如何预期共存且在确保安全可控前提下更好造福人类社会,成为全球人类共同面对的重大议题。

一年内国产大模型迅速迭代
采访中,王仲远谈及近一年国内大模型技术的发展变动。他称,2023年时,行业认为国内大模型还在追逐GPT 3.5。今年,国产大模型的平均水平已经超过GPT3.5,无限逼近GPT4。甚至在中文语境下的某些能力上,国内大模型超过GPT4,但GPT4本身也在不断迭代。例如最新发布的GPT4o整体性能、效果,甚至效率都有了显著提升,因此整个国产大模型还处在一个追赶的阶段。
大会现场,王仲远披露了智源研究院在语言、多模态、具身、生物计算大模型等方面的进展。包括智源研究院和中国电信人工智能研究院(TeleAI)联合研发并推出全球首个低碳单体稠密万亿语言模型 Tele-FLM-1T。针对大模型幻觉等问题,智源研究院自主研发了通用语义向量模型BGE(BAAI General Embedding)系列。以及为实现多模态、统一、端到端的下一代大模型,智源研究院推出了Emu3原生多模态世界模型。
王仲远表示,国产大模型达到可用、但并不非常好用的水平,GPT4之后,大模型可以进入到场景内进行快速迭代,但与之伴随的突破难度也非常大,包括算力资源、核心算法、系统工程等方面,如万卡以上的GPU如何实现芯片互联仍面临一定挑战。
近一年大模型迅速发展的因素中,Scaling Law(规模法则)成为与会嘉宾多次提到的关键。李开复表示,AI 2.0是有史以来最伟大的科技革命和平台革命,大模型Scaling Law的重要性在这个时代得以凸显——人类能够用更多计算和数据不断增加大模型的智慧,这条被多方验证的路径还在推进中,远未触达天花板。
月之暗面CEO杨植麟认可大模型是第一性原理,需要不断提升模型的规模,但其中最大的挑战是有一些数据并不一定有那么多。智谱AI CEO张鹏从实用主义角度表示,Scaling Law还在有效,还在前进。至于它能否帮助大模型达到顶峰,目前行业找不到一个确切的答案。百川智能CEO王小川从AGI的终点来看,要实现AGI除了规模,还需要有范式的改变,如大模型靠数据驱动学习做压缩,但目前的Scaling Law是做不到AGI的。面壁智能CEO李大海表示,Scaling Law是一个经验公式,是行业对大模型这样一个复杂系统观察以后的经验总结,随着训练过程中实验越来越多、认知越来越清晰,会有更细颗粒度的认知,如模型训练中的训练方法对Scaling Law、对智能的影响比较显著。

逼近GPT4之后的布局
采访中王仲远表示,国产大模型已经到了能够去支撑应用的阶段,所以他个人预测,未来两三年可以看到大量大模型应用的产生。至于具体分类,王仲远认为B端应用非常明确,几乎覆盖了所有行业。至于C端,行业普遍期待看到C端的爆款级应用。但类比移动互联网时代,当一个新技术或技术革命出现时,都需要一定的周期,需要天时地利人和,需要有技术能力。
具体到大模型落地C端产品,王仲远认为还需要模型足够低价好用,同时解决用户的真实痛点,因此对C端爆款应用需要保持一定耐心,“即使在大洋彼岸,也还没有出现C端的爆款应用。”王仲远称。
如果AGI时代到来,可能发生的技术演进路线是怎样的呢?王仲远认为,过去几年,绝大部分的科研关注度,包括产业的关注度,都在大语言模型的突破,目前大语言模型依然是单语言的模型,但除了文本数据外,还存在大量图像、视频、音频等多模态数据。当多模态大模型能够理解和感知、决策这个世界时,它就有可能进入到物理世界。如果进入到宏观世界与硬件结合,这就是具身大模型的发展方向;如果进入到微观世界去理解和生成生命分子,这就是AI For Science。
OpenAISora团队负责人Aditya Ramesh在与纽约大学助理教授谢赛宁的对话环节中表示,对于构建更加智能的具有推理能力的系统来说,语言模态确实十分重要,但从某种意义上来说,将语言信息以某种通用接口融入视觉信号中或许可以实现模拟任何事物的能力。随着模型规模的增大,其对于语言的依赖也会降低。
近期,海内外多模态领域更新频繁,包括AI初创公司Luma AI发布视频生成模型Dream Machine,短视频公司快手推出Kling大模型。对于行业现状,Aditya Ramesh表示,团队目前最关心的是视频生成模型的安全性及其对社会的影响,希望人们不要用Sora来发布错误的信息,也希望模型的行为符合人类的期望。很开心看到有其他实验室和公司从事视频生成模型的研发,有大量的人尝试使用不同的方法对于激发艺术和扩散模型领域的创新很重要。而“提高可控性”和“减少随机性”是Sora团队目前从合作方收到的最重要的功能需求。
AI安全是此次智源大会另一个重要议题,杨植麟同样认为AI安全非常重要,虽然不一定是当前最急迫的,但是一个需要提前去准备的事情。因为随着模型的进展,Scaling Law的发展是每N个月算力乘以10倍,智能会得到提升。杨植麟认为AI安全包括模型本身因用户而产生的恶意意图,以及在模型底层注入AI“宪法”框定模型的行为。
李大海认为,现阶段安全主要聚焦在基础安全与内容安全两个方向上,现在的大模型本质上是只读的,权重是固定的,推理不会影响权重。未来当用户将模型部署到机器人等终端上,模型能够去动态更新自己的权重后,安全问题将变成一个非常重要的问题。
对于近期的价格战问题,王小川表示,降价让更多个人与企业入场,同时令很多企业开始清醒,不再参与做大模型,而是“退”回来成为大模型的用户,减少资源浪费。
普京视察俄武装部队指挥部 听取特别军事行动进展汇报
据报道,俄总统新闻秘书佩斯科夫表示,普京从彼尔姆返回时在顿河畔罗斯托夫停留,视察了那里的俄武装部队指挥部。格拉西莫夫向普京汇报时表示,俄对乌特别军事行动区域联合部队正在按计划执行任务。据俄新社当地时间20日报道,俄罗斯总统普京视察了俄罗斯武装部队位于顿河畔罗斯托夫的指挥部,俄武装力量总参谋长格拉西莫夫向其汇报了俄对乌特别军事行动相关情况。00005月主要经济数据回落,央行接连“降息”,一批政策正出台丨一周热点回顾
其他热点还有:前5个月财政收入增长14.9%,美联储暂停加息。习近平会见比尔·盖茨16日,国家主席习近平在北京会见美国比尔及梅琳达·盖茨基金会联席主席比尔·盖茨。习近平对盖茨说,你是我今年在北京会见的第一位美国朋友。世界正在走出新冠疫情,人们应该多走动、多交流,增进了解。中美关系的基础在民间,我们始终寄希望于美国人民,希望两国人民友好下去。0003工信部指导腾讯做好重要业务系统安全稳定运行工作
4月12日,工业和信息化部信息通信管理局听取腾讯公司关于“3·29”微信业务异常情况汇报。据工信部网站消息,4月12日,工业和信息化部信息通信管理局听取腾讯公司关于“3·29”微信业务异常情况汇报,要求腾讯公司进一步健全安全生产管理制度、落实网络运行保障措施,坚决避免发生重大安全生产事故,切实提升公众业务安全稳定运行水平。0000落实生态环境保护、促进民营经济发展、推进制度型开放试点……上海市政府常务会议研究了这些重要事项
推动更多利于民营经济发展的重大政策落地,支持民营企业在现代化产业体系“主赛道”和数字经济、绿色低碳等“新赛道”上大显身手。上海市委副书记、市长龚正今天(28日)主持召开市政府常务会议,传达学习习近平总书记重要讲话和全国生态环境保护大会精神,传达促进民营经济发展壮大的意见精神,要求按照市委部署,抓好贯彻落实;抓好对接国际高标准推进制度型开放相关试点工作;持续加强政府自身建设。0000寿险改革成效显现,平安一季度净利同比大增48.9%
保险业全面回归。步入4月末,保险业迎来一季报大考。今年是上市保险公司按照监管要求执行新的企业会计准则(IFRS17)的第一年,新的会计准则旨在让保险公司更加稳健经营和高质量发展,各保险公司的业绩变化也因此更受关注。0000