腾讯混元大模型姗姗来迟,高管解说有这几点考虑
虽然此前腾讯集团CEO马化腾表示不急于推出半成品大模型,但在这样的技术迭代节点,缺席不行。
9月7日,腾讯终于通过腾讯云对外开放通用大模型“腾讯混元”,由腾讯全链路自研,拥有超千亿参数规模,预训练语料超2万亿tokens。token是指一段文本的最小独立部分,大模型中,token可以是一个单词也可以是一个字符,一般会对token数量进行限制以避免超过模型的最大处理能力。

作为“混元”的领队,腾讯集团副总裁蒋杰2012年加入腾讯,2020年完成腾讯广告投放端整合。广告业务也是混元大模型的重要“试验地”,除此之外,云、游戏、金融科技、腾讯会议、腾讯文档等超过50项腾讯业务与产品均接入混元大模型测试。
相较于国内百度、阿里,以及人工智能创业公司在今年上半年的高调与迅速,腾讯在通用大模型领域称得上“缓慢”。除了马化腾所解释的“早一个月把电灯泡拿出来不那么重要”外,采访中腾讯集团高级执行副总裁、云与智慧产业事业群CEO汤道生表示,通用大模型对计算要求非常高,数据的积累也花费漫长时间,且行业大模型的发布能够满足具体客户的需求。
此次“延迟”亮相的通用大模型有哪些不同?蒋杰表示,腾讯混元重点关注中文创作能力,提高了模型在场景中的推理能力,让模型能够更好地抗拒“诱导”,并通过自研的“探真”技术来优化普遍存在的幻觉问题。
OpenAI研究人员此前撰文表示,“即使是最先进的人工智能模型也很容易产生谎言,它们在不确定的时刻往往表现出捏造事实的倾向。而这些幻觉在需要多步骤推理的领域尤其严重,因为一个逻辑错误就足以破坏一个更大的解决方案。”OpenAI采取奖励每个正确推理步骤取代奖励正确结果的方式来矫正幻觉问题。
腾讯通过探真(truth forest)等技术降低大模型的幻觉,而不是“背题”等单点优化的方式。蒋杰表示,外界会用到知识图谱甚至搜索外挂来提高大模型的检索支持能力,如有些开源模型厂商所发布的大模型中,搜索增强技术就占比10%甚至更多,但这会导致不一样的幻觉问题。腾讯也会用到这些增强技术,比例并不高,在预训练阶段优化目标函数,“彻底解决幻觉问题是非常非常难的,只能从概率上做到更低。”蒋杰成说。
腾讯选择全链路自研的路径主要是为了技术迭代更快,也可以和内部业务及应用有更深度的结合。此外,腾讯有海量高并发业务,开源架构的大模型不能够支撑腾讯的业务体量。
相较于其他大厂或创业公司提速开源的动作,腾讯混元目前所有能力均开放给腾讯业务部门,各业务基于混元的能力上去和更多的应用结合,把选择的主动权交给了集团业务部门。
优先结合自身应用的考量还包括了对大模型落地C端还是B端,蒋杰称,大模型在B端产生大规模商业收入这件事还有待探索,目前腾讯通用大模型在成熟度与对复杂任务的处理能力方面还不够,因此很多严肃专业场景还不到“解锁”的时候。另外大模型结合自身应用也可以在一定程度上抵消大模型研发高昂的设备、训练、人员成本。
目前腾讯拥有13.3亿微信(合并WeChat)月活用户数,1.15亿视频付费会员,1亿音乐付费会员,外界颇为关注这样大基数的产品叠加大模型技术后会发生什么改变。蒋杰对第一财经记者表示,腾讯产品和应用要提供什么能力和服务,以及什么时间发布,会由业务部门自己决定。
最终公布了通用大模型产品的腾讯杀入了战局。目前行业共识一方面AIGC是大趋势,另一方面大模型的能力边界与呈现形式到底如何并无定论,判断算力底座与大模型应用谁会是下一个技术时代的颠覆者也为时过早。
汤道生对第一财经记者表示,AI服务包括应用层、模型层、基础设施层。腾讯会持续投入云服务底座的角色,腾讯会将合适模型推荐给客户,应用场景也是如此。
如果以容错率和任务复杂度为坐标轴制作一个2x2矩阵,蒋杰表示,当前国内发布的大模型应用主要集中在容错率高、任务简单的休闲场景。而在更具价值的严肃场景、工作场景和专业场景,大面积的应用还无法胜任。
因此,蒋杰表示腾讯大模型会更关注将提效基础能力做好——不胡言乱语,更安全,可靠性更强,具备更好的逻辑思维能力等,这些才是最核心的。
“扩免”已至关键节点,哪些疫苗优先级更高?
在WHO推荐所有成员国纳入国家免疫规划的10种常规疫苗中,尚有4种疫苗还未纳入中国国家免疫规划,分别是HPV疫苗、PCV疫苗、Hib疫苗和RV疫苗。我国国家免疫规划项目自2008年以来没有实质性扩容。近一年,随着HPV等关注度较大的疫苗地方免费接种试点推进和价格下降、新生儿数量下降等,“扩免”的业界预期再度提升。“‘扩免’已经到了一个比较关键的时期。”一名接近国家卫健委的专家告诉第一财经。锤子财富2024-05-07 07:37:320000佳士得香港秋拍释放哪些积极信号?内地千禧藏家逆势增长
在全球经济动荡、艺术市场大幅收缩的压力下,刚落幕的佳士得香港秋拍,释放出了一丝积极信号。在全球经济动荡、艺术市场大幅收缩的压力下,刚落幕的佳士得香港秋拍,释放出了一丝积极信号。锤子财富2023-12-05 15:53:080000恢复出境团队游目的地国家最新名单:英美、日韩等在列,平台签证咨询量涨288%
消息发布后,马蜂窝站内相关海外目的地热度平均涨幅超过150%,日本以高达350%的瞬时访问热度高居榜首。文化和旅游部办公厅8月10日发布关于恢复旅行社经营中国公民赴有关国家和地区(第三批)出境团队旅游业务的通知。0002淄博烧烤带火“味蕾游”,五一潮汕地区酒店预订增1200%
在淄博烧烤热潮下,“吃”成为不少人今年五一出行的重点。今年五一假期,将迎来出行高峰。交通运输部运输服务司副司长韩敬华在4月26日表示,预计节日期间旅游、探亲等出行需求十分旺盛,营业性客流量和公路网车流量将高位运行,从客流强度看,预计营业性客运量和自驾出行量将创2020年以来“五一”假期新高。从出行区域看,长三角、珠三角、成渝等城市群、中心城市、热门旅游城市将成为热门出行区域。锤子财富2023-04-28 14:27:370000理想汽车:第二季度营收286.5亿元 同比增长228.1%
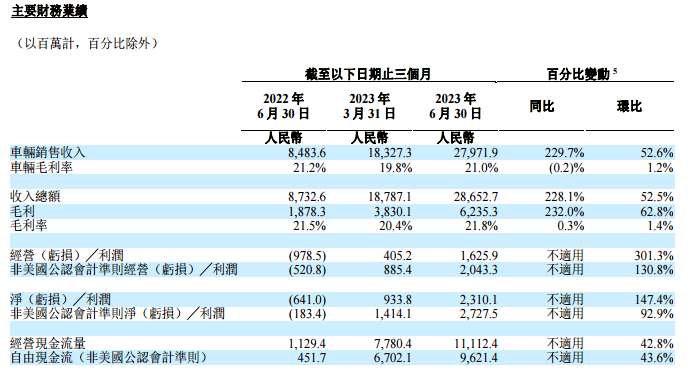
理想汽车在港交所公告,第二季度营收286.5亿元,同比增长228.1%,环比增长52.5%。8月8日,理想汽车在港交所公告,第二季度营收286.5亿元,同比增长228.1%,环比增长52.5%;第二季度净利润23.1亿元,上年同期净亏损6.4亿元。公告显示,2023年第二季度,汽车总交付量为86533辆,同比增长201.6%。锤子财富2023-08-08 17:32:420000