谷歌发布基础世界模型Genie 人工智能卷向“世界模型”
OpenAI和Meta之后,谷歌公布了世界模型领域相关进展。据谷歌官网,Genie是根据互联网视频训练的基础世界模型,可以从合成图像、照片、草图生成多种动作可控的环境。
随着谷歌入局,世界模型领域变得更加热闹,但谁能引领世界模型的风向,目前还难下定论。Sora是否世界模型此前已引起争议,反对者认为其视频生成方式与世界模型的因果预测有很大不同。从Sora发布的视频看,高保真的同时,模拟物理规律似乎是弱点,目前也还难以看出交互能力。谷歌Genie则在交互性上下功夫,可推断出生成环境中的潜在动作,但在视频真实性和清晰度的层面,Genie还未呈现出Sora般的水平。
专注2D平台游戏等
据谷歌介绍,过去几年,生成式人工智能模型能通过语言、图像甚至视频生成内容,谷歌引入生成式人工智能新范式,即生成式交互式环境(Genie),通过单个图像提示生成交互式、动作可控的环境。
Genie是一个110亿参数的基础世界模型,能从互联网视频中学习细粒度的控制,不仅能了解哪些部分是可控的,还能推断出生成的环境中的潜在动作。据谷歌放出的论文,Genie由三部分组成,由一个简单且可扩展的潜在动作模型推断每对帧之间的潜在动作,由一个视频分词器将原始视频帧转换为离散标志(token),以及一个动态模型,在给定潜在动作和过去帧token的情况下预测下一帧。
从谷歌放出的视频看,输入一张动漫人物闯关图片,能生成背景变换、人物连续跳跃且踩点准确的视频,动作具备相当的流畅度和合理性。输入一张真实世界的图片,图片中的人物、动物也能作出合理的跳跃或移动动作,但像素变得粗糙。

与Sora呈现出来的高清晰度、高真实度相比,Genie似乎不那么强调画面真实性,而是将重点放在潜在动作预测上。生成高真实度的视频并非目前Genie的着力点。谷歌介绍,Genie专注2D平台游戏和机器人技术的视频,但方法通用,应适用于任何类型领域并可扩展至更大的互联网数据集。只需一张图像就能创建全新的交互环境,这为生成和进入虚拟世界的各种新路径开启了大门。
据了解,动作可控是目前AI视频的一个难点,有创作者告诉记者,PIKA等视频生成工具多是做视差动画,看上去动了,但运动合理性还有很大改进空间,大幅度运动、人物对话较难实现。一段长视频要具备剧情,还保持在同一个风格里,AI很难做到,Sora通过多镜头巧妙地规避了这个问题,但还不能确认解决了问题。从这个角度看,AI理解物理世界并控制物体动作是一个重要方向。
世界模型之争
世界模型被认为是通往AGI(通用人工智能)重要路径。近期与世界模型或世界模拟器相关的进展频频,但各家的路径不同,谁能引领世界模型?
最早引起关注的Sora,OpenAI将其形容为作为世界模拟器的视频生成模型,并称通过扩大视频生成模型的规模,有望构建出能模拟物理世界的通用模拟器,但OpenA在Sora技术文档中并未详细介绍技术原理。目前看,Sora很可能重塑AI视频业态,但能否理解真实物理世界规律、是否具备世界模型的属性仍具争议。

一种代表性看法来自英伟达科学家Jim Fan,他指出,Sora是一个数据驱动的物理引擎,输入文本/图像并直接输出视频像素,是一个可学习的模拟器或世界模型。但Meta首席人工智能科学家Yann LeCun并不认可,他认为,Sora只是经过训练可以生成像素,但如果是以这种方式来了解世界运作,那注定是个失败命题。
“根据提示产生看起来最真实的影片并不代表系统理解物理世界,生成与世界模型的因果预测有很大不同。” Yann LeCun表示,合理影片的空间非常大,系统只需产生一个样本就算成功,而真实影片的合理连续空间小得多。
Sora视频确实显露出一些不符合物理规律的特征,例如,人物在道路上行走,仔细观察,会发现双腿出现了两次诡异互换;巨浪消失后,一个冲浪者还高高跃起;杯子摔碎的过程,液体先出现在桌面上,杯子才摔碎。有学者认为,世界模型需要对数据中没有的决策,通过推理得出,而Sora生成视频通过模糊的提示词引导,难以进行准确操控,没有准确地学到物理规律。Yann LeCun表示,更理想的方式是产生延续的“抽象表示”,消除场景中与可能采取操作无关的细节,这是JEPA(联合嵌入预测架构)的要义,是预测而非生成式。
Meta近日发布了V-JEPA。与谷歌Genie推测生成环境中的潜在动作不同,V-JEPA则是能生成视频中被遮挡部分,两者的共同点则在于对“推测”的强调。
Meta称,这个物理世界模型的早期示例擅长检测和理解对象之间的详细交互。V-JEPA使用从公共数据中集中收集的200万个视频训练,作为一种非生成模型,通过预测抽象表示空间中视频的缺失或屏蔽部分来进行学习,采用自监督学习方法,使用未标记数据进行预训练。与人类相比,人对周围世界的了解大多通过观察,人的内部世界模型可预测相关事件的后果,V-JEPA通过自监督训练也能了解世界运作的知识。在Meta展示的视频中,一个本子被遮挡了部分,V-JEPA能对被遮挡部分作出多种预测并生成视频。
巨头频有布局世界模型领域的动作,应用层面也跃跃欲试。有游戏从业者告诉记者,AI绘图的出现此前已极大加快其公司美术人员的工作效率,讨论角色进度的会议从一周一次加快到一周两次,游戏实时刷新的特点使AI工具还无法替代游戏引擎,但一些简单的短剧编辑器可能被替换。一名影视企业技术美术人员告诉记者,虽然还不能替代实拍或3D制作内容,但客户很多时候已希望在片子中引入AI风格,形成奇观。
守护3.3亿人心脏健康!创新设备下基层要看效用与价格
随着人口老龄化,中国的心血管疾病患病群体会越来越庞大。心脏是人体最勤勉的器官之一,分毫不怠。如果心跳漏掉一拍,可能是心动;如果心跳漏掉数秒,则性命堪忧。《中国心血管健康与疾病报告2021》显示,我国心血管病人数达到3.3亿,每5例死亡中就有2例死于心血管病。另有报告发布一项研究结果称,我国心衰患病率在过去15年间提高了44%,25岁以上的人群中心衰患者人数已经达到1210万左右。锤子财富2023-05-28 23:13:200000行业年报盘点丨“中字头”强势,去年上市公司业绩大多报喜
截至收盘,中铝国际、中工国际涨停,中铁装配、中国海诚涨超9%,中水渔业涨超8%。中字头个股今日再度走高,表现强势,截至收盘,中铝国际、中工国际涨停,中铁装配、中国海诚涨超9%,中水渔业涨超8%。Wind数据显示,主力资金今日流入中国平安逾7亿元,加仓中科曙光、中信证券超4亿元,中国中免、中国石油、中国移动等股获主力净流入额居前。0000美股全线上涨标普首破5600点,苹果市值接近3.6万亿
特斯拉实现11连阳。*三大股指上涨超1%;*中长期美债窄幅波动;*芯片板块发力,费城半导体指数创新高。周三纳指和标普500指数再次联袂创历史新高,在最新通胀数据和季度盈利报告之前,英伟达和其他华尔街权重股上涨带动市场情绪。截至收盘,道指涨429.39点,涨幅1.09%,报39721.36点,纳指涨1.18%,报18647.45点,标普500指数涨1.02%,报5633.91点。市场概述0000房地产寒意浸透家居装修业,有装修公司数月接不到业务
房子卖不动了,需要装修的家庭自然也就减少了。眼瞅着就要到2024年,但杨奕今年的业务,才不过五六单,这让他不免慌乱起来。这几日,遇到相熟的朋友,他总会央求对方给自己介绍几单业务,“有提成,介绍一单,能给你(提)好几千。”杨奕这样“游说”一位朋友。杨奕口中的“业务”,是家居装修。有着10多年装修设计经验的他,与朋友合伙开了一家装修公司。0001中国3月出口(以美元计价)同比增14.8%
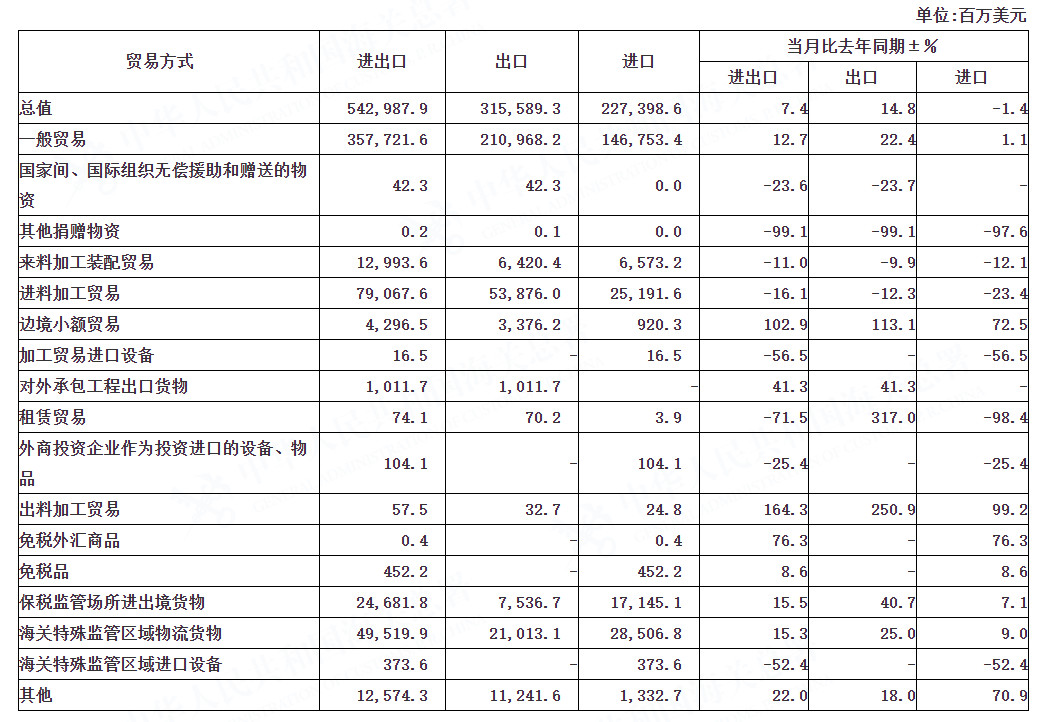
以美元计价,中国3月出口同比增长14.8%,3月进口同比下降1.4%;3月贸易顺差881.9亿美元。4月13日,海关总署数据显示,以美元计价,中国3月出口同比增长14.8%,3月进口同比下降1.4%;3月贸易顺差881.9亿美元。锤子财富2023-04-13 11:50:480000