ChatGPT板块爆发 国内企业聚焦突破算力束缚
近日,OpenAI以山姆·奥尔特曼(Sam Altman)回归公司CEO(首席执行官)职务、重新组建董事会的方式将路线之争暂时压下。而国内人工智能创业赛道在看过热闹之后,重新聚焦于眼前的算力问题解决。
2023人工智能计算大会上,中国工程院一局副局长唐海英表示,近期刚发生的戏剧性 OpenAI 事件,正是加速派和保守派之间矛盾的体现。对国内产业而言,人工智能的迅猛发展带来便利,也带来风险与挑战。特别是我国的科技界与产业界,应考虑如何利用大规模数据、模型、应用等优势,生成自己独特并能造福人类的AI。既要大胆探索、勇于创新,又要小心谨慎,预估各种风险,开展负责任的研究和应用。
中国工程院院士王恩东表示,虽然目前外界对AI的发展存在很多担心,但今天的计算发展仍处于初级阶段,AI也刚开始进入经济、社会与个人生活。未来可能人们生活的每个场景内都有一个大模型。人工智能发展的前景是美好的,但对算力的需求也是巨大的。
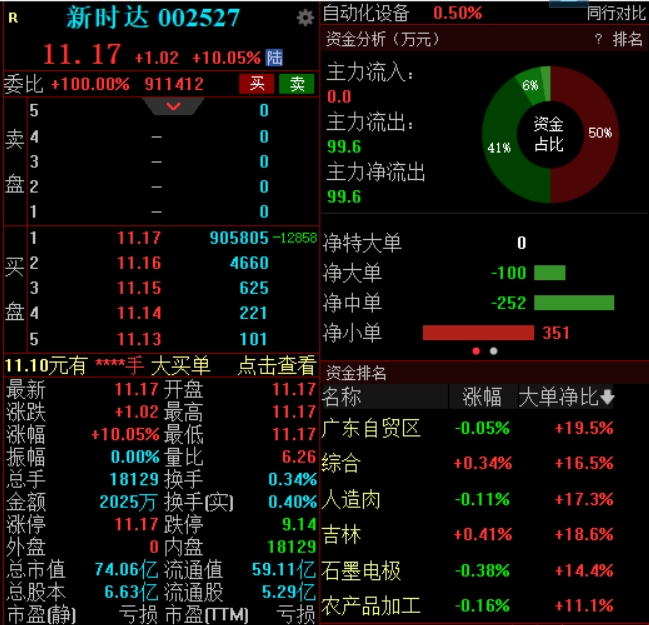
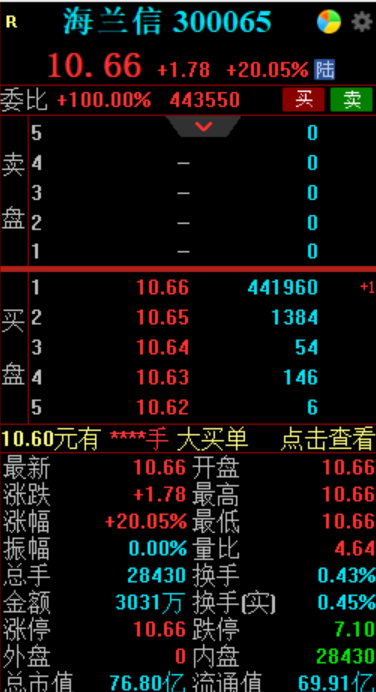
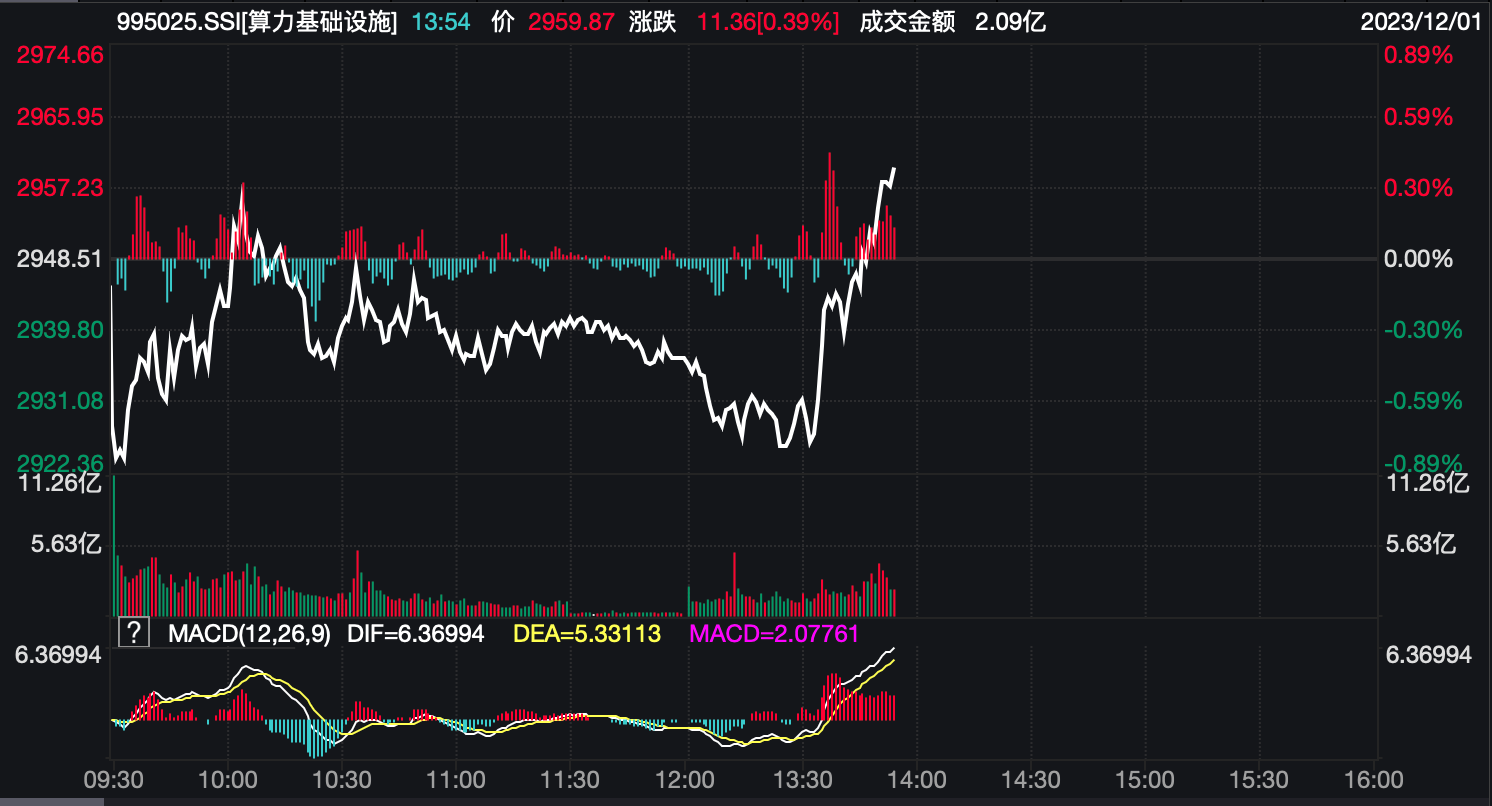
Wind数据显示,截至发稿,上证指数强势翻红,ChatGPT板块强势爆发,昆仑万维冲击20cm涨停,万兴科技、果麦文化升超15%,网达软件涨停,海天瑞声、云从科技、拓尔思集体走强。算力基础设施板块涨0.39%。
生成式AI引爆算力需求
大会现场发布的《2023-2024中国人工智能计算力发展评估报告》显示,中国智能算力规模增速快于同期通用算力规模增速。
IDC数据显示,预计到2027年通用算力规模将达到117.3EFLOPS(每秒进行百亿亿次浮点运算的能力),智能算力规模将达到1117.4EFLOPS;2022年至2027年,预计中国智能算力规模年均复合增长率达33.9%,同期通用算力规模年均复合增长率为16.6%。
浪潮信息高级副总裁、AI&HPC产品线总经理刘军表示,在生成式AI 的带动下,人工智能计算力的技术和应用趋势发生了较大的变化,可归纳为三个方面巨大的格局之变:计算范式之变、产业动量之变以及算力服务之变。
计算范式上,刘军表示,大模型和生成式AI 的发展驱动了产业对高性能、高互联的算力基础设施的需求,也推进了人工智能在云边端的覆盖。同时伴随着应用场景的多样化,底层的基础设施也呈现出多元化的发展。
其次,生成式AI带来了产业动量之变。生成式AI会重构现有的工作和生产方式,在内容创作、自动驾驶、零售、医疗等诸多领域改变人们的生活和生产方式,也带来了更大的市场机会。具体的产业栈上,AI算力、算法、应用服务等产业变量都在加速创新,成为创新加速器,在生态链上面催生出新的玩家。
第三,刘军表示,生成式AI将重构算力服务的模式和市场的格局。不同于以往云计算的服务方式,基础大模型的训练需要用大规模AI算力平台进行长时间的单一任务,进而带来高额训练成本。作为企业方,除了自己构建训练集群外,还可以通过采用算力服务等租赁方式来满足自己的训练需求,这也为算力服务的市场带来了新的机会。
在这些层面,机会伴随着挑战,尤其是如何在算力层面更好地支撑生成式AI创新应用。刘军认为应从算力系统、AI软件基础设施(AI Infra)、算法模型以及产业生态四方面进行综合考量。
刘军认为,目前国内外AI训练算力供给虽百花齐放,但由于每个厂商在开发过程中采用的技术路线不同,在接口互联协议方面存在较多不兼容问题,这也导致AI算力系统开发适配的周期长、定制开发投入大、业务迁移时间久等问题。
此外,由于大模型的训练对AI算力系统扩展要求很高。而对目前的行业、尤其在国内,企业在单GPU算力受限的情况下,为获得更大的训练性能,必须通过扩展集群规模来获得性能的扩展。其次,在数据存储方面,大模型已从原来的单模态向多模态、跨模态演进,其中会涉及到文本、图像、音频、视频等多态数据进行模型训练,训练数据集会达到 TB 级甚至 PB 级。
当集群的规模达到一定量级之后,刘军称,网络性能的波动会导致所有计算资源的利用受到影响,一旦出现故障,整个系统的连通性也会受到较大的波及。
算力压力面临生态挑战
解决之道在哪里?刘军认为首先应开放平台多元算力,首先是开放平台多元算力,打造高性能AI 服务器。在计算方面尤其要解决目前多元算力的问题。在可以预见的相当长时间内,行业一定会处于多元算力共存的局面,所以希望用一个统一的系统架构和接口规范来兼容各类多元AI 算力,从而保障AI算力的高效释放。
北京智源人工智能研究院副院长兼总工程师林咏华表示,目前国内在芯片性能方面的差距大概为三年。目前英伟达已发布H200,国内大多数AI大模型训练集群所使用的国内芯片个别能力接近H100、A100、A800,但更多尚未达到这些芯片性能的50%,这是目前的现状。
但需要注意的是,林咏华强调,芯片性能差距更大在于生态方面的差距。英伟达的成功不仅仅在于其芯片,更在于其软件栈CUDA(Compute Unified Device Architecture)的成功。近期应为宣布全球CUDA注册开发者数量超过300万。
人工智能与机器学习领域国际权威学者吴恩达此前曾评价CUDA的意义:“在CUDA出现之前,全球能用GPU编程的可能不超过100人,有CUDA之后,使用GPU变成一件非常轻松的事。”行业普遍认为,CUDA完善的编译器生态是英伟达GPU在高性能计算领域成功的关键,如易部署、开发接口灵活、编程语言适配、工具及代码库完备,且兼容Windows、Linux和MacOS多个操作系统。
反观国内市场,林咏华称,国内AI芯片厂商有40多家,每家厂商都有自己的软件栈,但整体份额加起来不超过10%,整个软件生态非常割裂,当然也面临产能受阻等客观问题。
这样的背景下,林咏华认为行业需考虑如何突破算力受限与生态壁垒,打破全球芯片与中国芯片之间的差异难题,即打破异构算力束缚。
一位业内人士对记者表示,生成式AI这种智能算力完全替代通用算力的可能性已经开始出现了。聚焦目前国产芯片的话,部分较好的产品,其单卡算力基本能达到300T,但由于英伟达独有的接口原因,基本上国内芯片计算能力以及互联能力综合能达到英伟达A100的水平,但与H100、H800相比,还有较大差距。另外,目前几乎全球所有开源系统都基于英伟达CUDA生态构建,而CUDA是闭源的,其他企业必须开发自己的生态。
“大模型或智算框架,国内企业都经过很多探索,去适应一个新的生态,这个过程非常漫长且痛苦,相应来讲,会有很多企业还是会继续选择英伟达,而非一些比较新兴的公司。这也是任何一种生态发展过程。”该人士表示。
国家统计局:今年青年人就业在8月份出现明显改善
付凌晖表示,随着经济持续恢复,稳就业政策显效发力,今年以来我国劳动力市场整体趋于活跃。9月15日,在国新办新闻发布会上,有记者提问,统计局上个月表示暂停发布分年龄段的城镇调查失业率,对这个数据的优化工作进行得如何。国家统计局新闻发言人付凌晖表示,关于分年龄段劳动力调查相关数据情况,国家统计局正在深入研究,如果有新情况,会及时对外公开。0000碳酸锂电池价格回归理性,过山车式价格变化背后有何逻辑?
锂资源供给完全能够满足市场需求,锂价的大幅波动是由于短期供需错配,未来将回归合理区间。上海钢联4月24日发布的数据显示,电池级碳酸锂均价报18万元/吨。自2022年11月下旬以来,电池级碳酸锂均价从最高点59.5万元/吨一度跌至17.5万元/吨,最大跌幅超70%。0000A股登上热搜,人民币升破多个关口,大涨行情能否延续丨火线解读
A股大涨,再度登上热搜。12月28日,人民币汇率狂拉,日内升幅涨超400点。与此同时,A股大涨,再度登上热搜。机构指出,短期,随着权重板块以及核心权重股的率先企稳,在北向资金大举抄底之际,市场情绪和信心暂时回升,A股也放量迎来大涨,反攻之际或预示着岁末以及跨年行情正式开启。A股放量大涨,发生了什么?锤子财富2023-12-28 20:34:330000成都网警破获一起编造传播证券市场网络谣言案
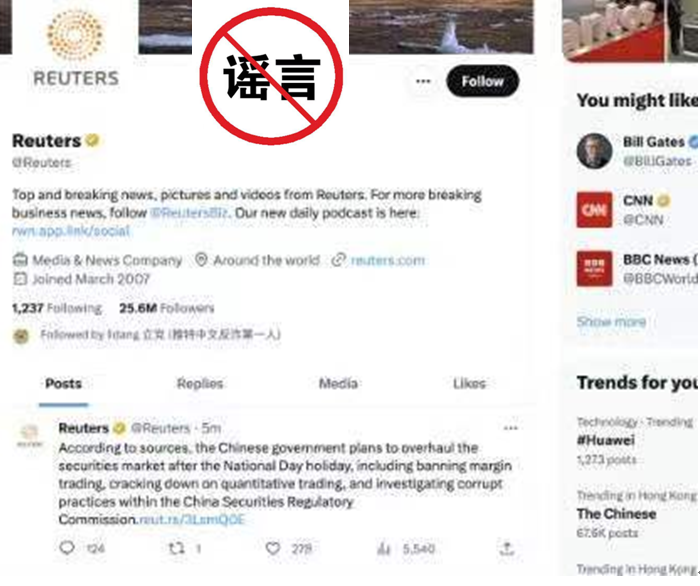
经查,王某出于主观臆断和寻求精神刺激,通过篡改境外新闻媒体的局部页面,对外发布自己编造的我国证券市场融资融券等政策的不实信息。近日,四川成都网警工作中发现,有不法人员利用境外新闻媒体的局部页面,编造我国证券市场融资融券等政策的不实信息。迅速传播、影响恶劣锤子财富2023-11-22 14:27:170001IP经济助力文旅复苏,北京环球度假区人气口碑双丰收
锤子财富2023-05-11 13:55:520001