当生成式AI遇上“超级大选年”,如何有效抵御风险|专家解读
2024年是全球超级大选年,同时,生成式人工智能(GAI)技术的突飞猛进也为选举之年带来了新挑战:由于技术可以产生欺骗性视频甚至提供虚假投票信息,该如何进行监管?
2月中旬,微软、谷歌、OpenAI等20家企业曾在第六十届慕尼黑安全会议上宣布,将共同致力于打击在今年选举中由AI技术产生的错误信息,不过外界对于这种行业自律协议在多大程度上能有效存疑。
欧洲工商管理学院(INSEAD)决策科学与技术管理学教授叶夫根尼乌(Theodoros Evgeniou)从事机器学习和AI研究已超过25年。在他看来,必须要学会区分什么是错误信息(misinformation),什么是虚假信息(disinformation)。前者是指错误或具有误导性的信息,但后者是为影响舆论或掩盖真相而有意散播的假消息。
“后者是有意为之,通常由不良行为者驱动。”叶夫根尼乌在接受第一财经记者采访时表示,据他观察,包括美国在内的许多国家都强调虚假信息和政治系统的网络风险是国家安全的首要风险。

有效管理风险
叶夫根尼乌认为,新一代AI有助于抵御网络危害,不过前提是我们能有效地管理风险。
“生成式AI开创了一个新时代,创造和传播近乎无限的内容已成为有形的现实。大型语言模型(LLM)(如GPT-4)和文本到图像模型(如Stable Diffusion)等工具引发了全球讨论。”叶夫根尼乌说,随着监管机构竞相追赶,出现了一些关键问题,涉及对在线平台的影响,更重要的是对互联网信任和安全的影响。
譬如,在今年1月,据媒体报道,美国新罕布什尔州当局就接手了一个案件,其中的涉案电话涉嫌运用AI技术模仿美国总统拜登的声音打给选民,目的是阻止人们在该州的民主党初选中投票。
2月8日,美国联邦通信委员会(FCC)宣布,禁止使用AI语音克隆工具进行自动电话呼叫,违者将面临高额罚款。
“这些AI工具可能会导致非法或有害内容或大规模操纵行为的增加,有可能影响我们对健康、财务、选举投票方式甚至我们自己的叙述和身份的决定。”叶夫根尼乌认为。
但他也强调,这些强大的技术也为改善我们的数字世界提供了重要机遇。
“这些工具可以作为信息战的武器,也可以用来抵御来自AI和网络的伤害。”他举例称,譬如谷歌和微软都已开始利用生成式AI来提高安全性,使安全专业人员能够更好地检测和应对新威胁。
又如,较大的在线平台已经在使用AI工具来检测某些内容是否由AI生成,并识别潜在的非法或有害内容。新一代AI可以提供更强大工具来检测网上的有害行为,包括网络欺凌或诱骗儿童、推销非法产品或用户的恶意行为。
叶夫根尼乌表示,不过,安全政策专业人员在依赖AI生成工具执行日常任务之前,需要考虑各种因素。
“以制定在线平台政策为例,制定一套有效、稳健且易于理解的政策通常需要数年时间,其中涉及与专家、监管机构和律师的多次磋商。就目前而言,让生成式AI工具来完成这种细致入微的工作是危险的,也是不精确的。”他表示,虽然这些工具可以提高政策专业人员的工作效率,但在创建和更新政策及其他法律文件时,生成式AI在多大程度上可以被认为是安全可靠的,还有待观察。
“明智的做法是保持谨慎,并考虑到生成式AI可能会使大量内容充斥互联网,从而使内容管理变得更具挑战性、成本更高,以及这些内容可能造成的大规模伤害。”他举例道,最早观察到的大型语言模型行为之一就是它们倾向于“产生幻觉”,创造出既不存在于用于训练的数据中,也不符合事实的内容。
“随着幻觉内容的传播,它们可能会被用来训练更多的LLM。这将导致我们所熟知的互联网的终结。”叶夫根尼乌表示,要避免这场灾难,有一个相对简单的解决方案: 必须让人类始终参入政策制定、审核决策和其他重要的信任与安全工作流程中。
他还补充道,LLM生成内容的另一个问题是混淆原始信息来源。
“这与传统的在线搜索不同,在传统搜索中,用户可以通过评估内容提供者或用户评论来评估可靠性。当用户无法区分真实内容和被操纵的内容时,就会产生巨大的政治和社会风险。”他表示。
暂停AI技术研究?
可以看到的是,生成式AI技术的突飞猛进引发了一波关于是否应暂停技术进步的讨论,今年3月29日,未来生命研究所发表公开信,呼吁所有AI实验室立即暂停训练比GPT-4更强大的人工智能系统至少6个月,被称为“人工智能教父”的杰弗里•辛顿、特斯拉首席执行官马斯克等上千人均签署了这封公开信,这封信中的主要内容为,AI实验室陷入了一场失控竞赛,但其研发者也恐怕不能理解、预测或可靠地控制这些数字思维。随后马斯克还在不少场合重复了自己的以上看法。
叶夫根尼乌对此认为,虽然“暂停”可能会让我们在短期内松口气,相信我们不会朝着某种不可预测的AI末日狂奔而去,但这并不是一个令人满意甚至切实可行的长期解决方案,尤其是考虑到公司和国家之间的竞争问题。
“相反,我们需要集中精力确保在线信任和安全不会受到这些技术的负面影响。”他强调,虽然技术可能是新的,但所采用的风险管理实践和原则并不一定是新的。
“几十年来,信任与安全团队一直在制定和执行有关误导性和欺骗性在线内容的政策,在应对这些新挑战方面有着得天独厚的优势。管理其他风险(如网络安全)的常见做法可用于确保生成式人工智能世界的信任与安全。”他举例道,例如,OpenAI在发布ChatGPT之前聘请了信任与安全专家进行“红队”演练。
在“红队”演习中,各位专家以与恶意行为者相同的方式挑战新产品。通过尽早暴露风险和漏洞的方式,“红队 ”专家有助于制定有效的策略和措施,最大限度地降低风险。
“OpenAI现在著名的‘作为由OpenAI训练的大型语言模型,我不能……’的这句对潜在危险提示的回应就是红队努力的直接结果。”叶夫根尼乌解释道,成为一名成功的“红队”成员所需的技能和创造力本身就是一个新兴产业。
他表示,随着我们的生活逐渐在很大程度上转移到网上,以及AI在各行各业的应用和产品范围的不断扩大,确保数字世界安全和有益,正变得越来越具有挑战性和紧迫性。
“在线平台已在其在线信任与安全实践、流程和工具上花费了多年时间。通常情况下,这些工作都是无形的,但现在是这些经验和专家占据中心舞台的时候了。”叶夫根尼乌表示,“我们所有人都必须共同努力,在与AI共存的过程中为人类指明前进道路,而不是被AI的阴影所笼罩。”
迪阿股份上半年净利同比下滑38.56%,董事长、总经理自愿降薪50%
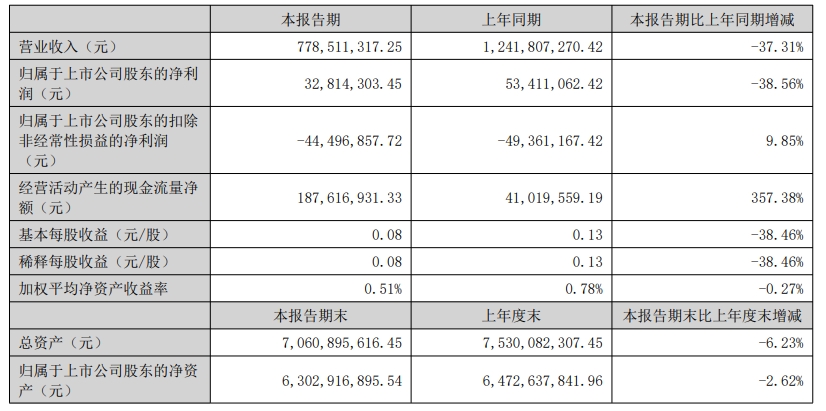
迪阿股份发布半年报,上半年,公司实现营业收入7.79亿元,同比下降37.31%。8月29日晚,迪阿股份发布2024年半年报,上半年,公司实现营业收入7.79亿元,同比下降37.31%。归属于上市公司股东的净利润3281.43万元,同比下降38.56%。锤子财富2024-09-01 08:02:380000零售股开盘活跃 中央商场录得4连板
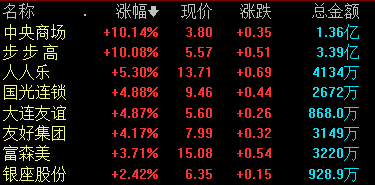
截至发稿,中央商场继续涨停,录得4连板,步步高、人人乐、国光连锁等跟涨。7月19日,零售股开盘活跃,截至发稿,中央商场继续涨停,录得4连板,步步高、人人乐、国光连锁等跟涨。据国家统计局近日发布的数据显示,上半年,社会消费品零售总额227588亿元,同比增长8.2%。其中,除汽车以外的消费品零售额205178亿元,增长8.3%。锤子财富2023-07-19 10:05:530000腾讯云继续“后退”做"被集成" 后续如何寻找云计算增量?
从集成商转为被集成商,削减集成类项目收入。云计算市场竞争激烈,互联网云厂商还在调整身姿。近日接受第一财经等媒体采访时,腾讯集团副总裁、政企业务总裁李强形容,腾讯云过去两三年已砍掉很多包袱。腾讯云从集成商转为被集成方,未来不会再参与大集成项目。锤子财富2024-01-18 19:38:060000消费品以旧换新政策效应逐步显现;华为原生鸿蒙10月8日开启公测丨明日主题前瞻
消费品以旧换新政策效应逐步显现,汽车、家电等重点消费品销量大幅增长;华为原生鸿蒙10月8日开启公测,机构称万物互联时代已来。①国内黄金零售市场价格持续攀升,黄金股或伴随金价上行迎来修复机会0000