欧盟《人工智能法案》如何影响开源模型监管?|专家解读
欧盟扫清了立法监管人工智能(AI)的最后障碍。
当地时间3月13日,欧洲议会以压倒性票数通过《人工智能法案》(下称"法案"),这标志着距离全球首部AI领域的全面监管法规的正式立法,仅有一步之遥。
欧盟国家将于5月正式批准该法案,立法预计将于2025年初生效并于2026年实施,其中某些条款将在今年内适用。
值得注意的是,免费、开源的模型的确获得了《法案》中的某些豁免。但如果它们被认为构成"系统性风险",开源并不能成为其免于遵守规定的理由,这表明更强大的开源模型仍将面临监管。
清华大学计算机系长聘教授,清华大学人工智能研究院视觉智能研究中心主任邓志东告诉第一财经记者,"作为一个特殊领域,欧盟出台《法案》,加强对AI的管控,给开源模型更大的豁免权,可促进人工通用智能(AGI)的研发沿着安全、正确的方向,以公开、透明的方式迭代演化,相信这会是未来的政策方向。"

能否推进开源?
开源即将模型的源代码和技术细节公开,并允许用户根据其自身需要对模型进行任意使用和修改。被认为有提高技术透明度,让用户更容易、更便宜地使用,惠及开发者降低迭代成本,防止垄断等好处。而闭源模型的源代码和技术细节则完全被其提供商控制,不对外进行公开,也不允许用户对这些模型本身进行更改。
邓志东对第一财经记者表示,开源大语言模型会造成一些安全方面的滥用或风险,但因为有全人类的共同参与,即使出现某些安全方面的问题,但囿于模型架构等方面的限制,可能也不会是致命的。
而对于闭源模型,邓志东认为其主要挑战是绝大多数人不知道那些闭源的AGI巨头都在干什么或打算干什么。
至于此举是否会使闭源模型在市场竞争上处于劣势,邓志东则表示,当前尚无全球AGI安全监管规则,由几家闭源公司决定人类的未来是非常危险的,特别是当一家AI头部企业正在追求百万块量级高端GPU算力的时候。 因此,相对于少数几个闭源模型竞争的不公平,全人类的安全更重要。
不过,在现实中可以看到,很多企业选择了"两条腿走路",即开源其较小的大语言模型,但在最大的和最先进的模型上选择闭源。
例如,一直坚持开源的法国人工智能初创公司MistralAI最新发布的Mistral-Large大模型尚未开源。谷歌开源的Gemma也仅为其轻量化的大模型版本,且谷歌仍可制定使用该模型的条款及所有权条款。而被特斯拉首席执行官马斯克起诉的Open AI,在GPT3.0版本之前会通过论文公开其具体的技术细节,但在3.5版本之后,则不再公开。在GPT-4发布时,连最基本的模型参数都没公布。
对此,邓志东向第一财经记者表示,"当AI产品或产业发展到相当成熟度,从开源走向有限开源甚至闭源是必然趋势。毕竟面临激烈的市场竞争,企业要生存、要发展,要追求商业利益的最大化,也需要平衡前期的巨大投入。这个商业底层逻辑可能是企业实现AGI大模型开源的难点。"
首部AI立法如何规范生成式AI
对于备受瞩目的生成式AI等功能强大的模型,《法案》计划进行分层处理。第一层涵盖所有通用模型,《法案》对其透明度作出明确要求,包括遵守欧盟版权法和详细说明训练方法和能源消耗。仅用于科研或开源的模型被排除在外。
第二层,如果通用人工智能(GPAI)用于训练的累积计算量大于10的25次方每秒浮点运算次数(FLOPs),将被认为具有"系统性风险",并将面临模型评估、系统性风险评估和减轻等额外要求。然而目前,只有OpenAI的GPT-4确定处于这一范围。此外,人造或操纵的图像、音频或视频内容则需要明确标记。
欧盟舆论认为,其他国家和地区可能会使用该法案作为未来AI治理的蓝图,就像欧盟的《通用数据隐私法规》(GDPR)所起到的作用一样。欧盟内部市场委员布雷顿就在法案通过后表示,欧洲现在是可信赖AI的"全球标准制定者"。
邓志东告诉第一财经记者,要加大AI领域重大方向性的全球安全监管力度,特别是对AGI的安全风险进行分级管控。
他认为,既不要妨碍AI的探索与创新活力,以期其蓬勃发展加快增进人类福祉,但也必须考虑人类的整体安全利益,处理好各个发展阶段的安全优先级别,在实践中把握好最佳AI风险管控时机。
《法案》的处罚力度同样可观,违反者最高可被处以3500万欧元或全球年营业额总额7%的巨额罚款以较高者为准。
不过,去年6月中旬,斯坦福大学AI研究实验室发布的一项研究显示,包括Open AI的GPT-4, Meta的LlaMa在内的10个主流大模型,均未满足《法案》草案的要求。其中Anthropic的Claude 1等三个大模型得分最低,倡导开源的Hugging Face与非营利组织BigScience开发的Bloom得分最高。
斯坦福研究团队在报告中表示:"主要基础模型提供商目前基本上没有遵守这些草案要求。他们很少披露有关其模型的数据、计算和部署以及模型本身的关键特征的足够信息。尤其是,他们不遵守草案要求来描述受版权保护的训练数据的使用、训练中使用的硬件和产生的排放,以及他们如何评估和测试模型。"
该研究团队表示,研究结果证明目前基础模型提供商遵守《法案》是可行的,并且《法案》的颁布和执行将为生态系统带来重大变化,在提高透明度和问责制方面取得实质性进展。
上海再度发文推动低空经济建设;工信部出手规范光伏制造行业丨明日主题前瞻
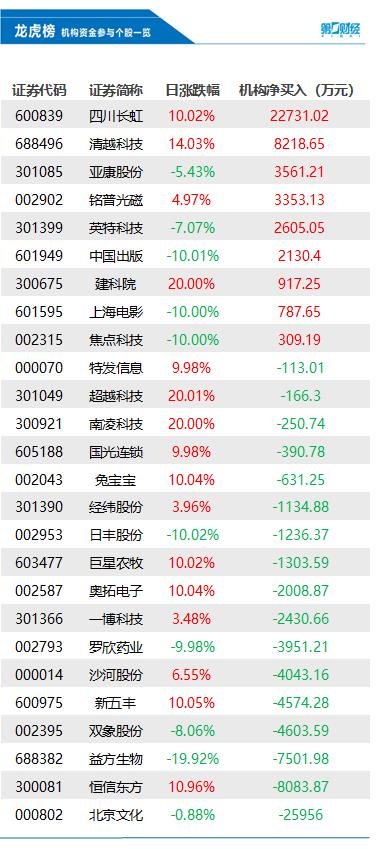
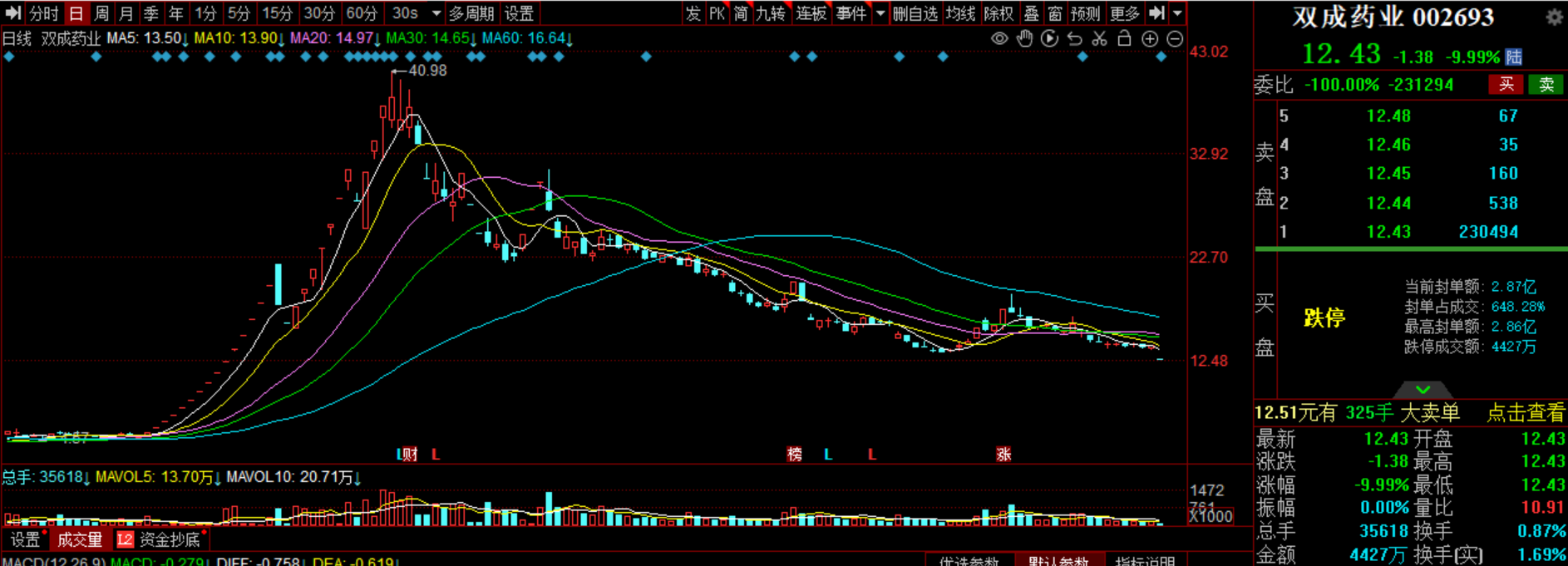
上海再度发文推动低空经济建设,机构称万亿级产业规模可期;工信部再出手规范光伏制造行业,头部企业有望受益。①上海再度发文推动低空经济建设,机构称万亿级产业规模可期上海市发展和改革委员会发布关于印发《深化推动新城高质量发展的若干政策举措》的通知。其中提出,在青浦、南汇等有条件的新城试点推动低空经济基础设施建设,支持在物流配送、特色文旅、应急救援、智慧城市、低空通勤等场景开展商业应用。0000机构今日买入这9股,抛售北京文化2.6亿元丨龙虎榜
机构净买入前三的股票分别是四川长虹、清越科技、亚康股份,净买入金额分别是2.27亿元、8219万元、3561万元。盘后数据显示,6月8日龙虎榜中,共26只个股出现了机构的身影,有9只股票呈现机构净买入,17只股票呈现机构净卖出。机构净买入前三的股票分别是四川长虹、清越科技、亚康股份,净买入金额分别是2.27亿元、8219万元、3561万元。锤子财富2023-06-08 17:59:130000走进数字政通:数字政务先行者
近年来数字政府建设加速推进,数字政通(300075.SZ)主营的数字政府核心平台“一网统管”,已成为数字中国建设成果最直观的体现之一。近年来数字政府建设加速推进,数字政通(300075.SZ)主营的数字政府核心平台“一网统管”,已成为数字中国建设成果最直观的体现之一。0000培育一流科技期刊要加强哪些方面?院士专家谈了这些关键
我国加快了培育世界一流科技期刊的步伐。近几年,SCI收录的期刊总量增长不到4%,中国进入SCI期刊数量增长了25%,进入Q1区期刊数量增长了1.8倍。作为科技成果发布和交流的载体,科技期刊正向支撑国家科技创新的基础性平台转变,直接体现国家科技竞争力和文化软实力。在培育世界一流期刊过程中,我国还应该加强哪些方面?锤子财富2023-11-01 19:17:560000聚焦清明|油价上涨不减出行热情,清明假期首日全国自驾出行同比增逾七成
虽然自驾出行成本增加,但人们出行热情有增无减。清明假期释放探亲旅游需求,虽然自驾出行成本增加,但人们出行热情有增无减。清明节旅游和探亲迎来高峰。据交通运输部消息,4月4日(清明假期首日),全社会跨区域人员流动量超过2.62亿人次,环比增长26.68%,同比增长70.34%,比2019年清明假期首日增长12.89%。0000