大模型商业落地,靠砸钱解决不了问题
生成式人工智能热此前在产业界掀起一股“百模大战”的热浪,不少企业纷纷斥资押注大模型。然而随着热潮逐渐淡去,各方也开始冷静下来。日前,第一财经记者从多方了解到,企业在大模型商业化落地,推动实际效益转化转化方面还存在诸多痛点。
在算力资源方面,沐曦科技创始人、董事长兼CEO陈维良对第一财经记者指出,大模型的训练、实施都需要巨大的算力,但当下算力的供给和需求之间存在着非常大的矛盾。“高效的算力正在支撑着生成式人工智能的发展,因此算力是一个基本需求,而如果我们不能降低AI的算力成本,实际上会限制它的推广程度。”陈维良认为,矛盾的解决路径就在于要进一步降低算力成本,提高GPU利用率。
国盛证券曾经估算,GPT-3训练一次的成本约为140万美元,对于一些更大的LLM模型,训练成本介于200万美元至1200万美元之间。今年1月平均每天约有1300万独立访客使用ChatGPT,对应芯片需求为3万多片英伟达A100GPU,初始投入成本约为8亿美元,每日电费在5万美元左右。
事实上,由算力短缺为大模型商业落地带来的问题远不是砸钱就能解决的。一位人工智能行业资深从业人士告诉记者,因受算力制约,多数大模型需要借助云端算力来帮助训练。但是,由于训练数据的敏感性,多数企业仅愿意将大模型的训练数据留存在本地部署,而这就构成了一对无法调和的矛盾。
此外,在闪马智能创始人、董事长兼CEO彭垚看来,算力成本高昂只是当前大模型商业化落地过程中的痛点之一。他指出,目前市场上的很多大模型都已经具备了很大数据量,甚至一些开源的模型已经诞生,因此数据的积累就已经花费了大量的资金和时间。而在这一背景下,对很多应用型的企业来讲,接下来需要把已有的学术资源变成业务落地性的模型。
“这里面对企业蕴含着两大挑战,第一是算力投资,模型训练需要投入巨大的算力资源,这需要企业持续的资金支持;第二个挑战则是在如何形成在行业数据方面的优势,这考验着企业对落地行业的理解,例如怎样将非常专业的处理数据标注出来。”事实上,记者了解到,当前能够进行专业数据标注的人才并不多,业界多数跨行业的合作都是为了解决数据标注的问题。例如此前华为联合上海联通、华山医院等发布了医疗大模型Uni-talk。
日前,“小模型”的概念也开始进入人们的视野。其实,小模型的概念一直伴随着大模型而存在,只不过此前大模型的概念过于如日中天罢了。在业界不少人士看来,“小模型”或能够在大模型之外提供一种更为经济的解决方案。
从概念上看,小模型并不是与大模型概念相对立的存在。根据任拓大数据研究院院长苏迭的定义,大模型从技术和训练内容来看位于生成式人工智能的最底层,对大模型训练的作用是建立基本的认知,让其具有泛化能力。这可以通俗理解为小学通识教育,会识字,会加减乘除。
而大模型之上还有中模型和小模型。中模型是基于大模型通过学习行业数据而建立的,对于中模型的训练集内容主要是某个具体行业的领域特征,类似中学的学科教育,历史地理,物理化学。
位于最顶端的是场景小模型,类似大学专业,土木工程、航空航天、工商管理。它是一种任务模型。小模型是基于中模型以及具体场景的数据而建立的,并且可以利用每家企业实际业务数据精调模型,帮助企业解决具体工作中问题。
从训练参数量来看,与大模型几十上百亿的训练参数量相比,小模型则更加聚焦于具体行业,训练参数量也会相对小得多。此前微软曾推出过一款训练参数量仅13亿的小模型产品ocra。而另一方面,从训练的角度来看,小模型的训练可借助端侧算力设施,在本地化部署的同时能够保证数据的安全。
对于品牌来说,大模型成本惊人难以入手,而行业中模型虽然能更垂直,但每家企业、每个品牌的应用场景各不相同,实际操作起来仍困难重重。唯有更具体的小模型,既“接地气”地直接指向实际场景,又成本可控,让企业品牌们能够在当前降本增效的大趋势下,兼顾布局。有业内人士对记者指出,当前市面上多数所谓的“大模型”产品从训练参数的定义来看应该是“小模型”。这些产品主要聚焦医疗、工业、电商等垂直领域。
上述业内人士对记者表示,大模型尽管具备强大的的学习能力和知识储备,但是高昂的训练和推理成本往往让企业望而却步。此外,大模型推理时延大,能耗和碳排放高等问题,也都限制了它在终端侧的使用。不过,小模型在应用时也存在数据标注的问题,相关人才的短缺问题依旧需要解决。
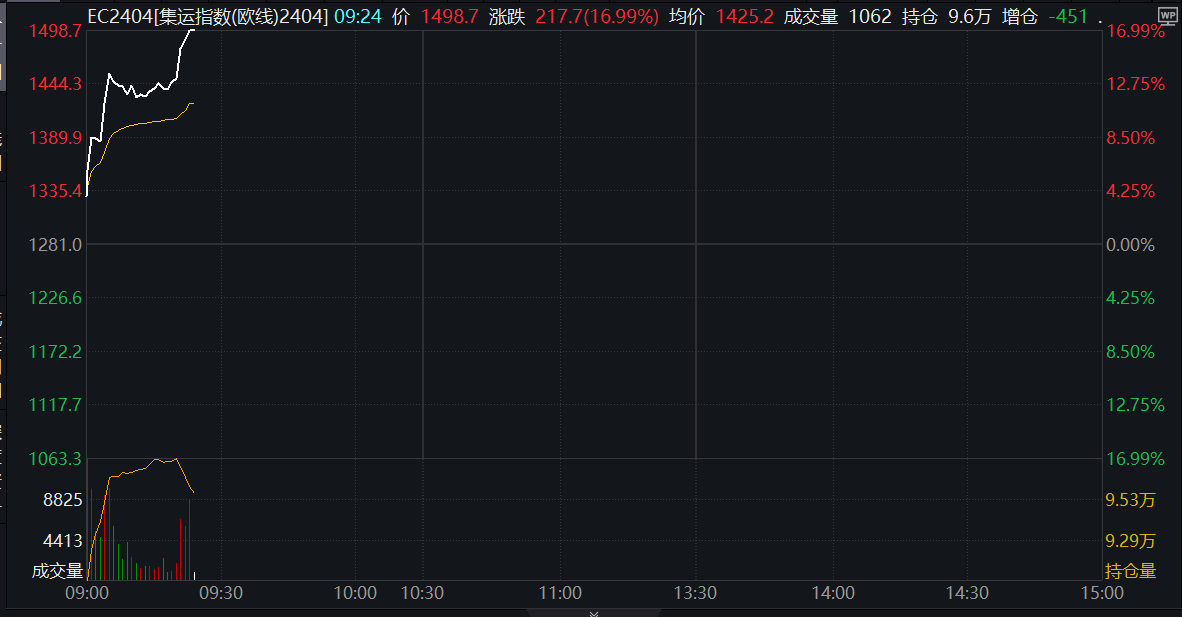
集运指数(欧线)期货主力合约快速拉升,触及涨停
集运指数(欧线)期货EC2404、EC2406合约的交易保证金比例调整为19%,涨跌停板幅度调整为17%。12月26日,上期所欧线集运指数主力合约日内触及涨停,涨幅16.99%,现报1498.7点。12月25日晚间,上海国际能源交易中心连发数个公告。上海国际能源交易中心发布通知称,经研究决定,自2023年12月25日(周一)收盘结算时起,交易保证金比例和涨跌停板幅度调整如下:锤子财富2023-12-26 10:01:300000地方财政4月份收入大增64%,为何收支矛盾仍突出
今年地方财政收入大增主要是去年同期基数低,实际增速与经济增速相近,且土地收入仍大幅下滑,叠加刚性支出有增无减,基层财政收支矛盾依然较大。4月份地方财政收入表现相对亮眼,但从接受第一财经采访的几位基层财政人士的反馈看,并没有数字表现得那么乐观。他们坦言,目前基层财政收支矛盾仍比较大,日子依然难。0000英伟达宣布为游戏提供定制化AI模型代工服务 游戏股大幅拉升
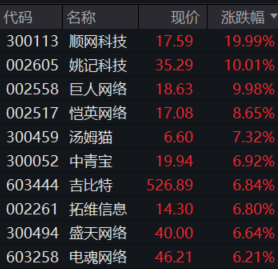
截至午盘,顺网科技、姚记科技、巨人网络涨停。5月29日,游戏股持续走高。截至午盘,顺网科技、姚记科技、巨人网络涨停,恺英网络涨超8%,中青宝、汤姆猫、吉比特等多股跟涨。消息面,英伟达宣布,推出适用于游戏的NVIDIAAvatarCloudEngine(ACE),这是一种定制的AI模型代工服务,可通过AI驱动的自然语言交互为不可玩角色(NPC)带来智能,从而改变游戏。锤子财富2023-05-29 12:58:310000机构今日买入这15股,抛售南网储能2.24亿元丨龙虎榜
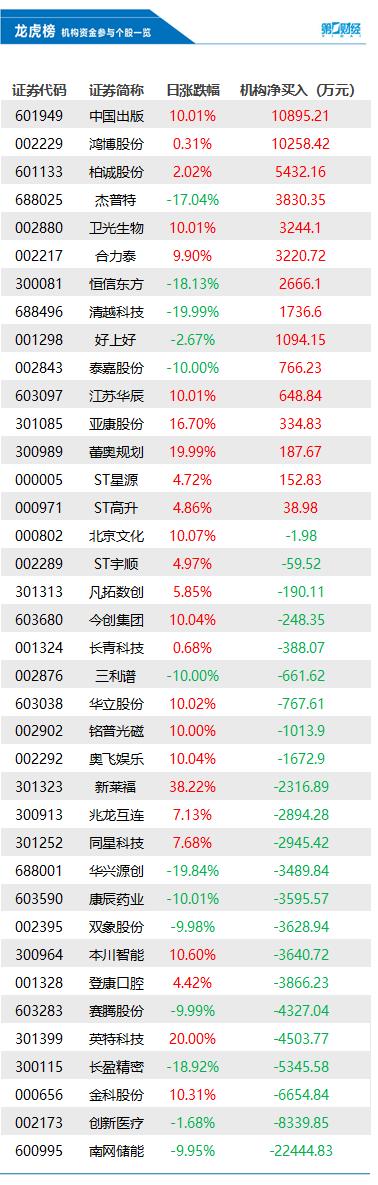
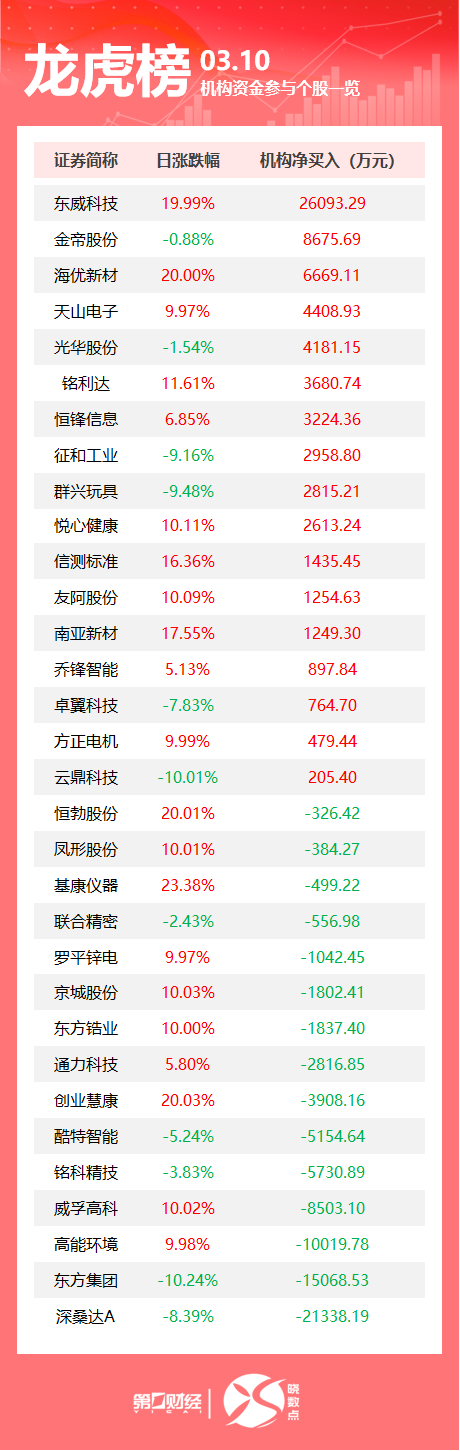
机构净买入前三的股票分别是中国出版、鸿博股份、柏诚股份,净买入金额分别是1.09亿元、1.03亿元、5432万元。盘后数据显示,6月6日龙虎榜中,共38只个股出现了机构的身影,有15只股票呈现机构净买入,23只股票呈现机构净卖出。机构净买入前三的股票分别是中国出版、鸿博股份、柏诚股份,净买入金额分别是1.09亿元、1.03亿元、5432万元。锤子财富2023-06-06 18:02:150000补发工资!多位银行高管获补2023年度薪酬超200万元
上市银行普遍建立了薪酬延期支付和绩效薪酬追索扣回相关机制。按照惯例,在2024年年底,多家上市银行披露了高管2023年度薪酬的补发情况,其中,有多位银行高管2023年度补发金额超过200万元。其中,2024年12月7日平安银行公告了9位领取薪酬的相关董监高人员已确认的2023年度税前薪酬的其余部分。0000