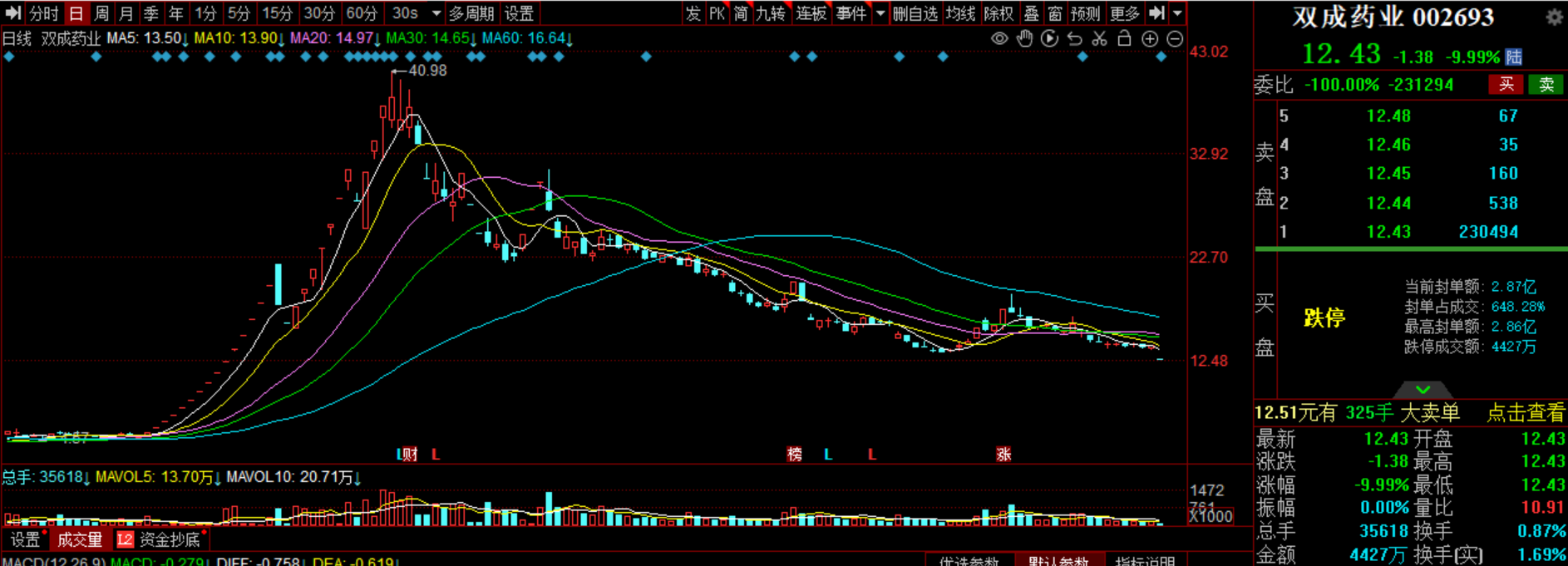
字节火山引擎称不做大模型 ,H800芯片将是云厂商标品

“火山引擎自己不做大模型,首先服务好国内做大模型创业的公司,”4月18日,火山引擎宣布为大模型公司提供算力与服务支持,接受采访时,火山引擎总裁谭待对第一财经记者表示,目前火山的任务一方面是算力供给,另一方面是搭建云原生机器学习平台,帮助企业应用好算力,进一步提升效率,把大模型训练得又快又稳定。
此前有消息称,字节跳动加入国内AI大模型竞赛,大模型团队由Tik Tok产品技术负责人朱文佳负责,应用场景包括抖音与TikTok的搜索功能、AI生成图片视频等。投资端与行业端也对字节跳动自研大模型抱以期待。但此次,颇受外界关注的火山引擎并未发布大模型产品,而是宣布发布自研DPU(数据处理器)等系列云产品,并推出新版机器学习平台:支持万卡级大模型训练、微秒级延迟网络,弹性计算可节省70%算力成本。基于自研DPU(中央处理器分散处理单元)的GPU(显示处理器)实例,相比上一代集群性能最高提升三倍以上。
算力问题是当下包括大模型公司在内的诸多公司客户的首要需求。此前腾讯发布高性能计算集群,缓解大模型趋势下的算力压力。所谓“高性能计算集群”,主要采用腾讯云星星海自研服务器,搭载英伟达最新代次H800 GPU,服务器之间采用3.2T超高互联带宽,为大模型训练、自动驾驶、科学计算等提供高性能、高带宽和低延迟的集群算力。
谭待认同当下的算力压力,他称,大模型还在发展初期,面临数据安全、内容安全、隐私保护、版权保护等许多问题。但可以预见的是,大模型将带动云上AI算力急剧增长,AI算力的工作负载与通用算力的差距会越来越小,这会为各家云厂商带来新的机会,同时也会对数据中心、软硬件栈、PaaS平台带来新的挑战。
对于算力缓解的具体方式,谭待对第一财经表示,H800芯片是一个标品,所有云厂商都会用。网络带宽设计也一样,不论是提供1.6T(指带宽,每秒数据传输率)还是3.2T,均各有特点。核心1.6T有其适合的场景,该类带宽性价比更高。如果追求3.2T的传输速度,未来支持到万卡级别——即用一万张高性能GPU卡做分布式的并行训练时,需要更复杂的网络结构。
相对来说,谭待称,火山机器学习平台的一大优势是内外同款,比如在集团内部,通过抖音平台推荐广告进行大规模场景训练。另对外,火山也合作了生物制药、自动驾驶等行业合作方。“这些实战经验非常重要,平台好不好,关键是有没有在真实的、大规模的场景中经历打磨,”谭待称。
谈及当下涌现的大批大模型公司,作为服务与技术提供方,谭待对记者表示,垂类行业客户与通用型大模型客户均有。但在2022年,行业中更多的反而是垂直类行业,因彼时包括推荐算法或自动驾驶行业都显露出模型越来越大的趋势,当时火山便做了很多准备。直到去年底今年初,基础大模型公司爆发出来,火山也发现之前积累的技术与经验可以用上,同时也根据新诉求进行优化。当下大模型客户类别上,谭待透露称,大约是通用型大模型公司占比三分之一,垂直行业公司占比三分之二。
作为重要的云服务厂商,此前阿里云宣布发布ECS企业级通用算力型U实例,价格对比上一代主售实例最高可下降40%,同时推出对象存储预留空间产品,价格最多可降70%。此外,阿里云还向开发者推出“飞天免费试用计划”。对于当下云厂商之间即将爆发的价格战,谭待对第一财经表示,火山也通过技术进行性价比的提高。例如通过火山与字节跳动国内业务并池,基于内外统一的云原生基础架构,抖音等业务的空闲计算资源可极速调度给火山引擎客户使用,离线业务资源分钟级调度10万核CPU,在线业务资源也可潮汐复用,弹性计算抢占式实例相比常规产品最高优惠80%以上,进而实现资源的高利用率和极低成本。
以抖音推荐系统为例,火山方面表示,工程师用15个月的样本训练某个模型,5小时就能完成训练,成本只有5000元。火爆全网的抖音“AI绘画”特效,从启动到上线只用一周多时间,模型由一名算法工程师完成训练。
同时,谭待对第一财经表示,成本是云计算的关键竞争力,但成本问题需要通过技术手段可持续地做好,而不是通过短期的商业手段,后者不可持续。
瞄准“服务消费”,上海2035年服务零售比重将超60%
2023年上海服务消费对社会零售总额的贡献率接近60%,比商品零售额贡献率高出10多个百分点。为了激发消费潜能,正在建设国际消费中心城市的上海把重点瞄准了“服务消费”。0000中国这些能源企业进了世界500强 | 新能源头条
通威股份的光伏业务营收已远超农牧业务。最新的《财富》世界500强排行榜8月2日发布,通威集团排名第476位,这也是通威集团首次进入世界500强。数据显示,该集团2022年营业收入达319.4亿美元,实现利润16.36亿美元。在净资产收益率方面,通威集团以42.9%的净资产收益率,在中国公司中位列首位,在全球位列第34位。0000工信部:优先开展“元宇宙 工业制造”等行业应用标准研制
按照急用先行的原则,重点加快研制元宇宙术语、参考架构等基础通用标准,优先开展“元宇宙工业制造”等行业应用标准研制。9月18日,工信部科技司就《工业和信息化部元宇宙标准化工作组筹建方案(征求意见稿)》公开征求意见(以下简称《征求意见稿》)。《征求意见稿》指出,当前,元宇宙正处于快速发展阶段,面临认识不统一、应用不规范、伦理问题突出等挑战,亟需通过标准规范和引导元宇宙行业健康有序发展。0000合资燃油车平替,自主品牌A0级电动车加速崛起
过去销量依赖A0级市场的新势力车企将面对五菱、比亚迪等巨头的直接竞争。以飞度、POLO等合资燃油车型主导的A0级汽车市场,正在被中国品牌纯电动汽车加速取代。0000