大模型开源潮流涌动 开启商业化前奏
闭源商业化的“百模大战”暂告段落,开源大模型仍旧热闹。
今年7月Meta推出开源且免费的大型语言模型LLama 2后,基于该模型微调的大模型不断涌现。此外,阿联酋阿布扎比技术创新研究所推出大参数模型Falcon 180B,国内8、9月份推出的开源大模型则包括阿里云Qwen-7B、Qwen-14B,百川智能Baichuan2-7B、Baichuan2-13B等。近日,香港中文大学贾佳亚团队还联合MIT发布长文本开源大语言模型LongAIpaca,号称全球首个70B参数长文本开源大语言模型,显示开源之潮还在继续涌动。
业界和学界对大模型开源感到兴奋。截至发稿日,以“LLama 2”为关键词在全球知名AI开源社区Hugging Face检索模型,有超6000个结果。百川智能创始人王小川透露,截至9月初,旗下两款开源大模型下载量超过500万。
大模型开发者林峣(化名)告诉记者,7月他发布了基于baichuan-13B微调的大模型,没想到8月底该模型在Hugging Face的下载量超160万次。他还在做开源大模型微调,在与其他做大模型的技术人员交流中,他发现很多公司为了较低成本和高效率,也在基于开源模型做微调。
越来越多AI工作者和企业参与进大模型开发,悄然改变了大模型生态。不久之前,业界还在争论谁“造轮子”(做大模型)谁“用轮子”(基于大模型开发应用),高昂的训练成本将中小型企业挡在大模型开发的门外,似乎只能面对不低的大模型服务定价。如今,事情发生了改变。
开源潮流涌动
从GPT3.0开始,OpenAI便不“Open”了,基于GPT3.5开发的ChatGPT火爆全球后,OpenAI还推出了收费版本。一众类GPT大模型一开始也以闭源方式呈现,不少商业公司将开发的大模型用于自身业务优化并对外开放合作。
大模型分为训练和推理两个过程,前者将大模型训练成型,后者即为应用。由于训练大模型需极大算力,开发成本高昂,业界多有关于不需“重复造轮”的讨论。例如,入场做大模型后,百度创始人、董事长兼首席执行官李彦宏屡次呼吁行业聚焦大模型的应用层,称创业者“卷大模型没意义,卷应用机会更大”。业内另一种声音则是通过大模型开源,在免除前期高昂模型训练成本的情况下引入更多参与者,加速大模型生态进化。
对难以入场训练大模型的企业而言,使用其他企业的闭源大模型服务有成本偏高的弊病。记者从使用GPT大模型服务的SaaS厂商了解到,用GPT4替代200名客服的成本达数十万美元。
基于长远考虑,北京智源人工智能研究院院长黄铁军近日接受第一财经记者采访时则表示,技术本身不断迭代演进,不能封闭在少数公司里,第三方参与者汇聚成洪流,将来可能成为大模型时代的技术底座,而不是变成某个公司作为运营商的形态。
在学界和业界的强劲需求下,开源之潮涌动。今年年初Meta推出LLama大模型后,一场源代码泄露风波,促使基于LLama构建的多个大模型涌现,Meta“从善如流”,7月发布了LLama 2开源可商用版本。国内,北京智源人工智能研究院于6月发布开源可商用的悟道3.0大模型,随后,百川智能、阿里云等进入开源大模型领域。

开源大模型涌现后,生态变化明显。林峣向记者回忆道,LLama开源极大推动开源大模型社区繁荣,业界发现可以基于LLama用较少成本在一些场景中逼近ChatGPT的效果,随之Ziya、Linly、Chinese-LLama-Alpaca等汉化版LLama出现,后续还出现许多原生中文开源模型。得益于生态活跃,林峣的大模型项目已发布了基于baichuan2-13b、LLama-30B、Qwen-7B等主流开源大模型微调的模型。记者所在的一个数百人大模型交流群中,每天都有从业者交流如何匹配客户需求及开源大模型相关技术细节。
对业界而言,除免费商用、部署成本较低之外,开源大模型还有一些难以取代的优势。林峣告诉记者,开源意味着自主可控、可在开源大模型基础上按需自行训练定制,使其更好应用于自身业务。而闭源模型如文心一言、讯飞星火等仅提供接口,无法再进行训练,OpenAI的大模型提供了训练接口,但训练时可能涉及企业机密数据泄露问题。
使用外部闭源大模型已引发业界关于数据泄露的担忧。此前,三星在内部使用ChatGPT等外部AI工具,曾导致机密信息外流,今年5月,有消息称三星担心传输至生成式AI平台的数据被存储在外部服务器上,已禁止员工使用ChatGPT、谷歌Bard等生成式AI工具。
开源之后
对大模型企业而言,开源与闭源并不矛盾,企业在开源与闭源、收费与免费之间选择,阿里云是在闭源大模型推出后,发布了免费可商用的Qwen-14B和Qwen-4B-Chat等,百川智能则是在推出开源可免费商用的多款大模型后,9月底推出闭源大模型Baichuan2-53B,并开放该模型API接口且启动商业化。
“厂商开源参数量较小的模型可产生影响力、构建生态,对于参数量更大的模型则可商业化。或者开源大模型厂商可收取商用授权费,或在开源模型后售卖云服务、算力、模型定制化服务。” 林峣认为,这是开源大模型厂商可能的盈利路径。
虽然开源大模型目前还在市场竞争初期,不少模型并未收费,但业界仍有探索盈利的动作。今年6月发布的开源大模型ChatGLM2-6B一开始商用并不免费,7月,智谱AI和清华KEG实验室才决定该模型可免费商用。同时拥有闭源大模型和开源免费大模型的百川智能、阿里云等企业,推出开源免费大模型客观上也有打开知名度的作用。
大模型不仅在训练时需要算力,在推理时也需要算力,记者了解到,从业者获取开源大模型后进行微调和推理,计算量小的情况下或只需一张显卡,商用后则免不了部署算力。云厂商可承接这部分算力需求,一批云厂商近期也闻风而动。
百度智能云此前已推出企业级一站式大模型平台千帆,9月还发布了千帆大模型平台2.0,将内置主流大模型数量增加至42个;腾讯云TI平台8月接入LLama2、Falcon等超20个主流模型,支持大模型直接部署调用且可全程低代码操作;阿里云魔搭社区也在积极接入主流大模型,包括baichuan 2系列、InternLM-20B等。
此外,目前企业使用闭源大模型服务存在一定的安全顾虑,闭源大模型不仅源代码不被外部使用者掌控,还部署在特定的外部云服务器上,相比之下,开源大模型可定制化、可避开某些数据泄露风险的特点突出,企业可以选择部署在自有服务器或其他终端上,这带来了潜在商业机会。LLama 2已与高通展开合作,高通计划2024年在旗舰智能手机和PC上支持基于LLama 2的AI部署,推出生成式AI应用,实现用户隐私保护及个性化。
在应用大模型的问题上,隐私保护和个性化服务尤为重要。在近期第一财经记者参加的一场行业论坛上,高通AI产品技术中国区负责人万卫星谈到,AI处理的重心正向边缘端转移,大模型可根据终端侧数据提供个性化服务,且不需依赖任何网络连接,数据留在终端,可解决隐私问题。
或是考虑到开发者利用开源大模型微调或推理的成本,目前不少开源大模型的参数量低于GPT4等商用闭源大模型,多为70亿或130亿参数。有业内人士指出,这些参数较小的模型转而在预训练时使用大量数据,以提升最终表现,应用至垂直领域,大模型性能表现仍很强大。
上海书展:每卖出1张门票,捐出1元支援书业纾困
今年上海书展推出三项举措,支援河北涿州等地因暴雨遭受重大损失的图书发行企业。8月9日下午,2023上海书展举行新闻发布会。今年相关活动总数约850场,其中主会场上海展览中心467场,特色分会场142场。锤子财富2023-08-10 08:12:000000李旭红:如何理解数据资源进入财务报表的财税价值︱天竺语税
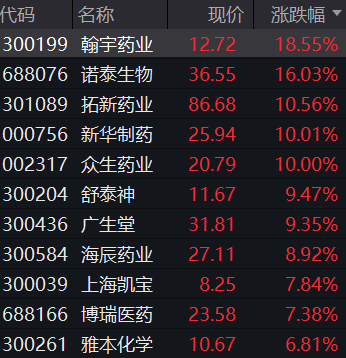
不久的将来,企业各类数据分级分类处理进一步完善,当一个内部标准化能够共享使用的数据基础构建完成之后,企业的财税管理也将进入“轻系统,重工具”的新阶段,而财务人员也将提升成为“业务财务人工智能数据分析”的复合型人才。0000新冠药概念股逆市上涨;电力板块跌幅居前丨早市热点
中船系、高压快充、电力板块跌幅居前,存储芯片板块回调。5月23日,三大指数早盘表现震荡,截至午盘,沪指跌0.58%,深成指跌0.12%,创业板指跌0.21%。医药医疗股全线爆发,新冠药概念股领涨,多股涨停,CPO概念午前拉升;中船系、高压快充、电力板块跌幅居前,存储芯片板块回调。一起回顾上午的市场热点。【新冠药概念股集体拉升】锤子财富2023-05-23 12:10:130000半年预亏200亿元,债券面临违约风险,又有房企敲响警钟
一年间亏损额度扩大逾15倍。在恒大资不抵债,碧桂园(02007.HK)超2000万美元票息到期未付的消息相继爆出后,又有地产公司被曝出票据面临违约风险。8月14日盘后,远洋集团(03377.HK)发布公告称,因未能按时支付约2094万美元的票据利息,导致将于2024年到期的美元债券停牌。0000